
Opaaaa!
Estamos de volta para colocar a mão no código! Vamos iniciar o desenvolvimento da infraestrutura como código do Azure SQL Database para posteriormente o mesmo ser adicionado à pipeline que iremos criar no Azure DevOps. Vamos lá.
Para instalar o Terraform verifique o link a seguir:
https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli
Depois de instalar o Terraform vamos instalar o Visual Studio Code, pelo link:
https://code.visualstudio.com/download
Abra o VS Code e clique no icone de Extensões do lado esquerdo e escreva no campo de busca superior Terraform, clique no icone que tiver Hashicorp Terraform e selo da Hashicorp em baixo, depois disso clique em Instalar (Install):

Agora vamos abrir as pasta aonde estão nossos repositórios: Clique na parte superior em Arquivos (File), Abrir Pasta (Open Folder…) e encontre a pasta onde estão seus repositórios e clique em Abrir (Open):

Agora vamos iniciar o desenvolvimento, crie os seguintes arquivos dentro da estrutura de pasta da pipeline de iac do azure sql database:
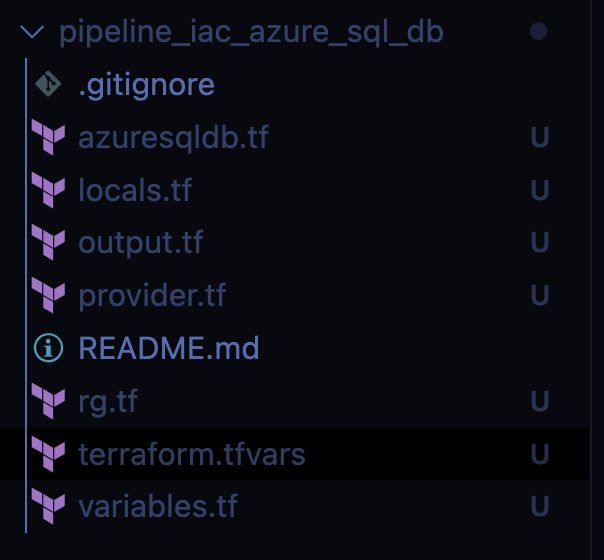
Abra o arquivo provider.tf e insira código a seguir:
terraform {
backend "local" {
}
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "3.48.0"
}
}
}
provider "azurerm" {
features {}
subscription_id = "seu_subscription_id"
}
Precisamos declarar as variáveis que serão utilizados nos recursos abaixo, edite o arquivo varibles.tf:
variable "rg" {
description = "Resource Group que será criado|utilizado na criação dos recursos de banco de dados"
}
variable "regiao" {
description = "Região ao qual os recursos serão criados"
}
variable "ambiente" {
type = map
default = {
d = "dev",
h = "hml",
p = "prd"
}
}
variable "env" {
default = "d"
validation {
condition = contains(["d","h","p"],var.env)
error_message = "Argument 'env' must be either 'd' (dev), 'h' (hml) or 'p' (prd)"
}
}
variable "nome_sistema" {
description = "Nome do sistema ao qual os recursos serão destinados"
}
variable "storage_account_tier" {
description = "Tipo de Storage Account que pode ser Standard ou Premium. Por padrão será Standard"
default = "Standard"
}
variable "storage_account_repl_type" {
description = "Tipo de Replicação de Storage Account que pode ser LRS, GRS, RAGRS, ZRS, GZRS and RAGZRS. Por padrão será LRS"
default = "LRS"
}
variable "admin_user_login" {
description = "Usuario para logar no servidor e banco de dados"
default = "admindb"
}
variable "admin_user_passwd" {
description = "Senha do usuario para logar no servidor e banco de dados"
sensitive = true
}
variable "db_collation" {
description = "Collation do banco de dados."
default = "SQL_Latin1_General_CP1_CI_AS"
}
variable "db_max_size" {
description = "Tamanho máximo do banco de dados. Por padrão 10GB"
default = 10
}
variable "db_sku_name" {
description = "Especifica o tipo de perfil de banco de dados que será criado. As opções são: GP_S_Gen5_2,HS_Gen4_1,BC_Gen5_2, ElasticPool, Basic,S0, P2 ,DW100c, DS100. Por padrão será Basic. https://azure.microsoft.com/en-us/pricing/details/azure-sql-database/single/"
default = "Basic"
}
Vamos criar mais algumas regras onde, para o caso de o ambiente ser produtivo onde vamos forçar a utilização de features que nos permitam ter redundância e performance como storage premium e replica de leitura (ainda não disponível para esta versão do provider, no futuro atualizaremos o post.). Para criar as condições basta comparar o resultado de uma variável com um valor seguido do ? onde a primeira parte é em caso verdadeiro utilizar o valor setado e os : aplica-se uma condição se-não em caso retorno falso da primeira expressão setar este valor, ficando da seguinte forma: condição ? (então) verdadeiro : (se-não) falso. Abra o arquivo locals.tf e cole o texto:
locals {
ambiente = lookup(var.ambiente,var.env)
storage_account_tier = var.env == "p" ? "Premium" : var.env
read_replica_count = var.env == "p" ? 1 : 0
zone_redundant = var.env == "p" ? true : false
tags = {
env = var.env
ambiente = local.ambiente
}
}
Após o provider vamos criar o Resource Group que irá comportar nossos recursos, abra o arquivo rg.tf:
resource "azurerm_resource_group" "rg" {
name = var.rg
location = var.regiao
}
Agora vamos abrir o arquivo azuresqldb.tf agora e começar a desenvolver a criação do resource de banco de dados:
resource "azurerm_storage_account" "storage_account" {
name = "sc${var.nome_sistema}${local.ambiente}"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
account_tier = local.storage_account_tier
account_replication_type = var.storage_account_repl_type
}
resource "azurerm_sql_server" "mssql_server" {
name = "sqlserver-${var.nome_sistema}-${local.ambiente}"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
version = "12.0"
administrator_login = var.admin_user_login
administrator_login_password = var.admin_user_passwd
tags = local.tags
}
resource "azurerm_sql_database" "mssql_db" {
name = "sqldb-${var.nome_sistema}-${local.ambiente}"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
server_name = azurerm_sql_server.mssql_server.name
collation = var.db_collation
tags = merge(local.tags)
}
Para saber qual é o ID do banco de dados gerado vamos criar um output no arquivo output.tf:
output "azure_db_sql_id" {
value = azurerm_sql_database.mssql_db.id
}
Por fim, para não precisar digitar as variáveis obrigatórias no momento do plan e apply, vamos declarar as variáveis e valores das mesmas no arquivo terraform.tfvars:
rg = "TerraformAzureSQLdb"
regiao = "eastus"
env = "p"
nome_sistema = "contabilidade"
admin_user_passwd = "P@ssW0dComPl3x"
Após popular todos nossos arquivos vamos agora executar nosso Terraform para verificar se tudo esta sendo criado de forma esperada antes de criarmos a pipeline.
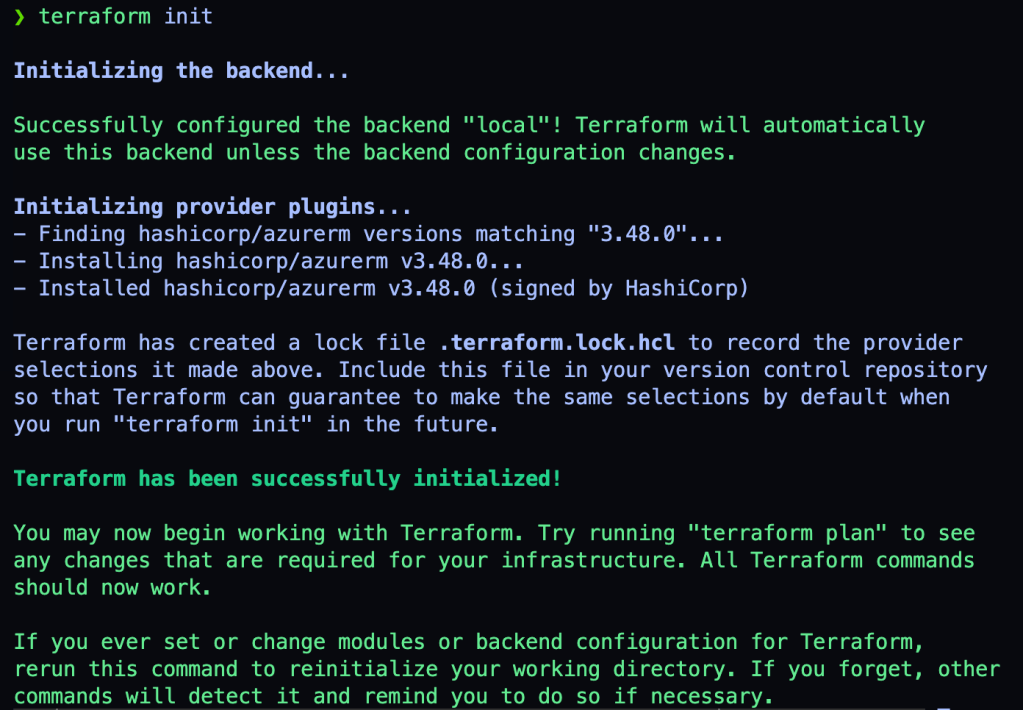
Para iniciar vamos executar:
terraform init
Este comando irá baixar o provider do Azure, o azurerm.
Depois disso vamos validar a sintaxe do código declarado:
terraform validate

Como podemos ver ele mostra um aviso dizendo que o recurso que cria o server que irá alocar o banco de dados esta deprecado e que na versão 4.0 será descontinuado, isso também esta explicito na documentação do recurso, logo após o warning podemos ver que a validação foi um sucesso, vamos seguir com o plan:
terraform plan
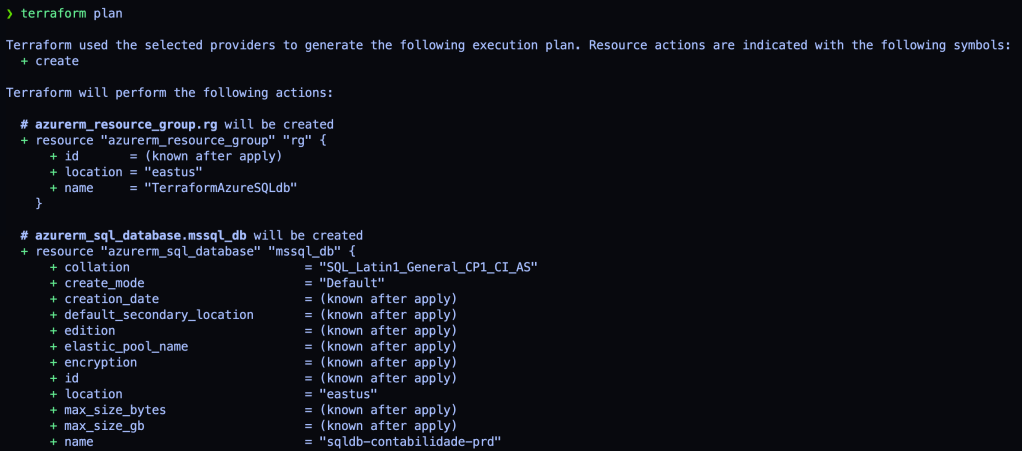
Veremos todos os recursos que serão criados e as configurações determinadas nos arquivos azuresqldb.tf. Vamos agora criar efetivamente com o apply:
terraform apply --auto-approve
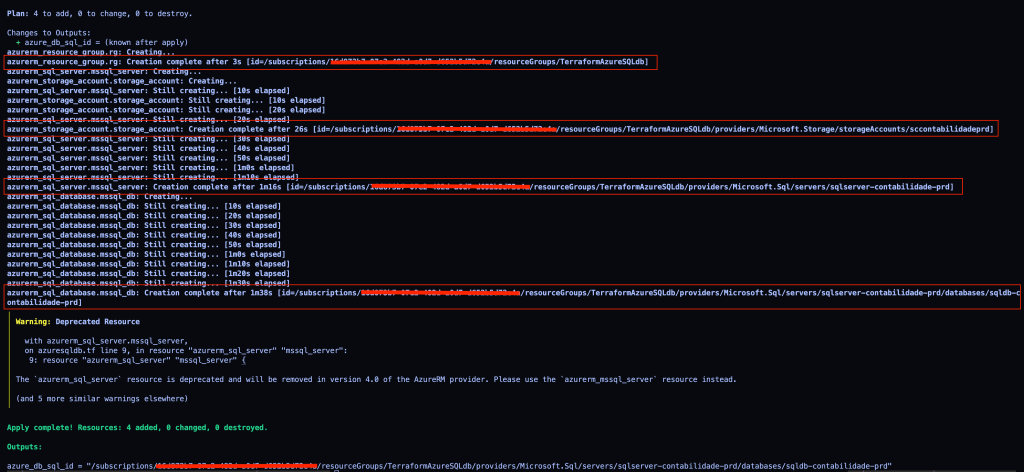
Recursos criados, vamos conferir no console:
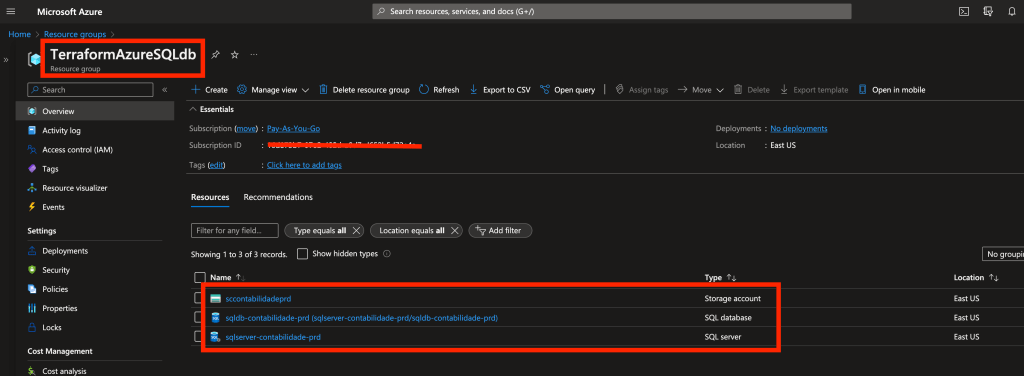
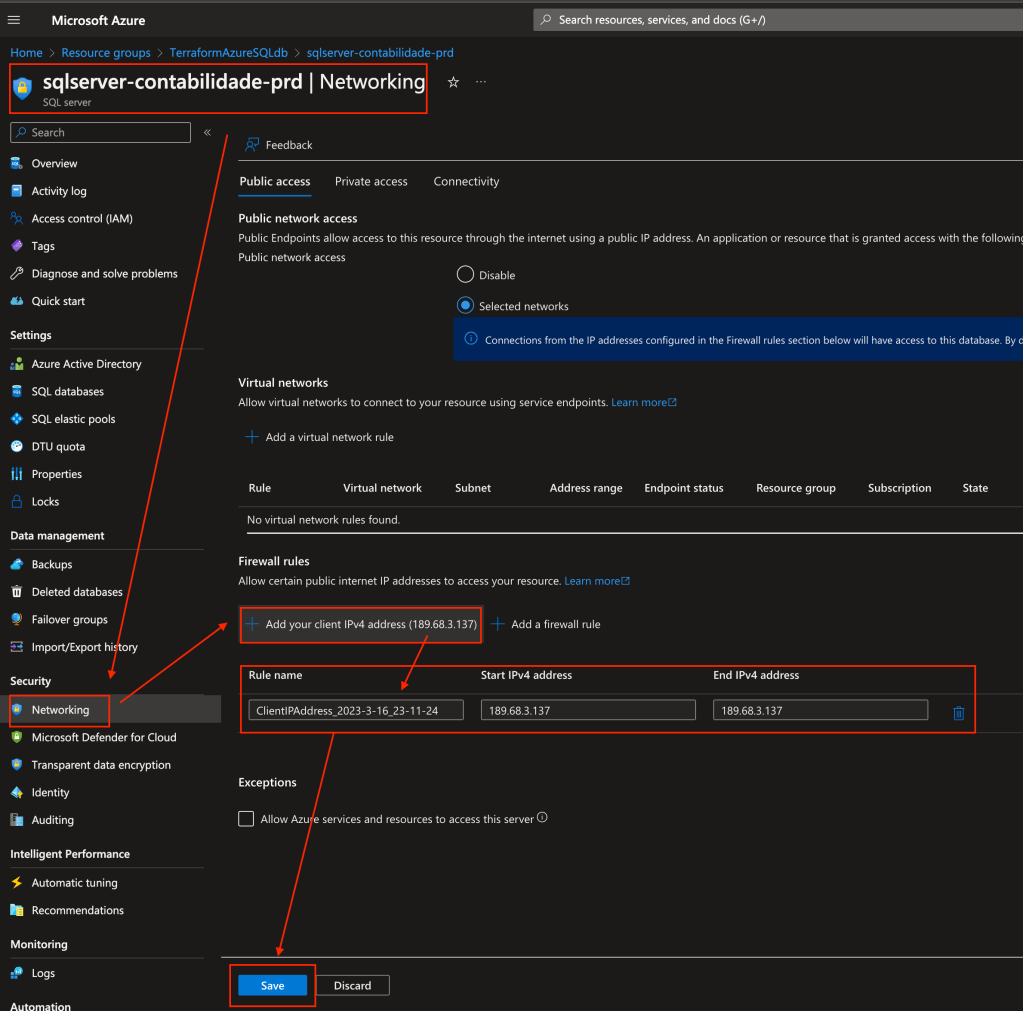
Agora vou liberar o acesso ao server a partir do meu ip, basta clicar no recurso do azure sql server, depois clicar em Network, terá um campo para adicionar o seu ip externo para ser liberado, clique no + e depois em salvar:
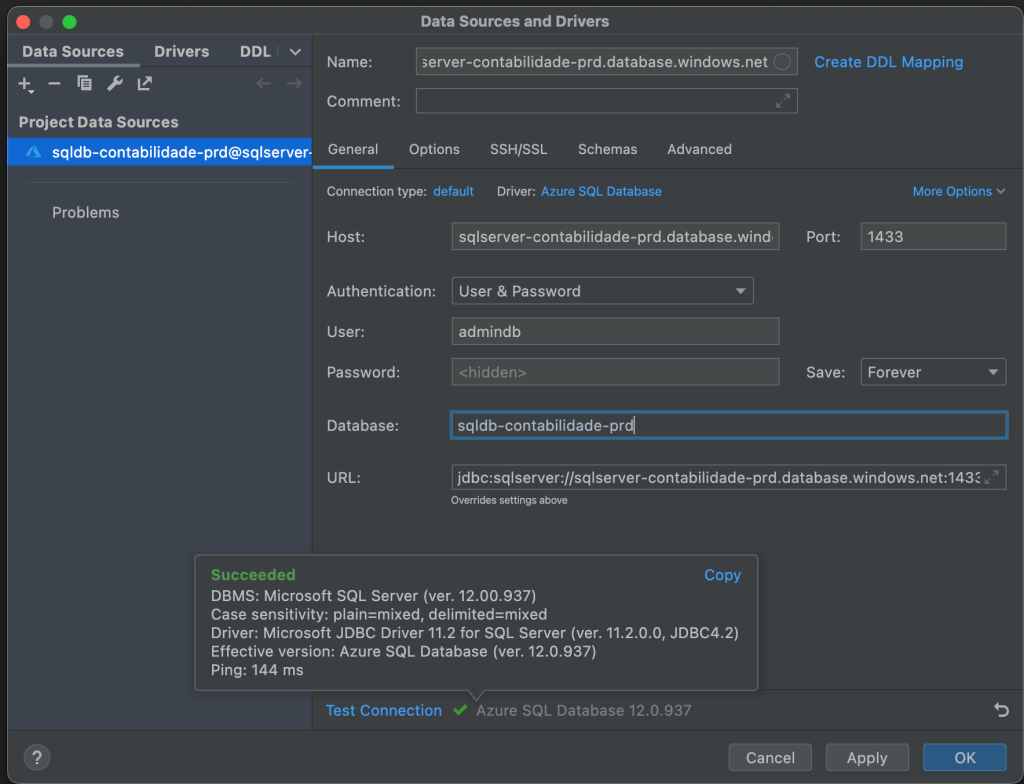
Com isso já podemos configurar nossa conexão e esta tudo funcionado conforme o exemplo abaixo:
Como tudo funcionou bem podemos agora destruir nossa infraestrutura pois o objetivo era montar o módulo de criação do nosso azure sql database. Para destruir a infraestrutura basta executar:
terraform destroy
Escreva “yes” para confirmar a destruição dos recursos:

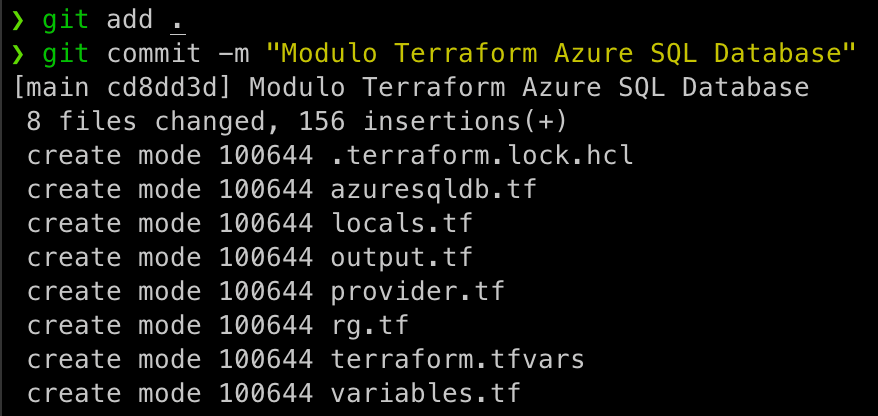
Por fim vamos subir as alterações para o Github, executando:
git add .
git commit -m "Modulo Terraform Azure SQL Database"
git push

No próximo post vamos desenvolver mais um módulo terraform, fiquem ligados!
Até a próxima pessoal!
