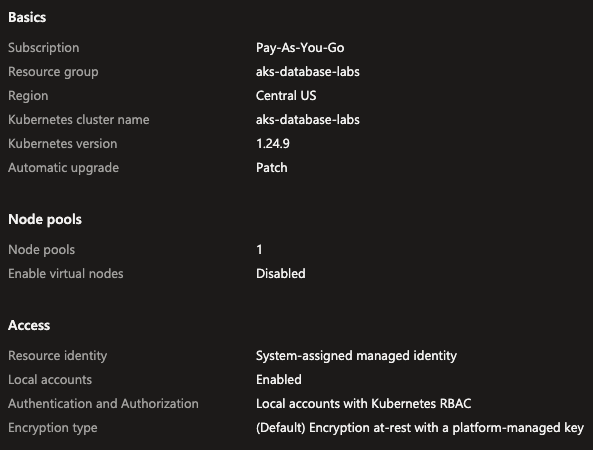
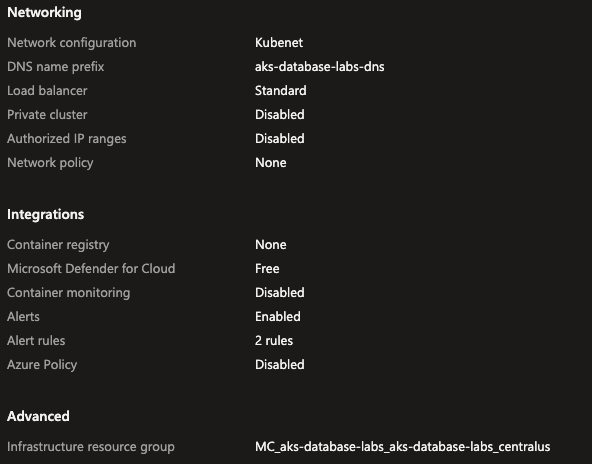
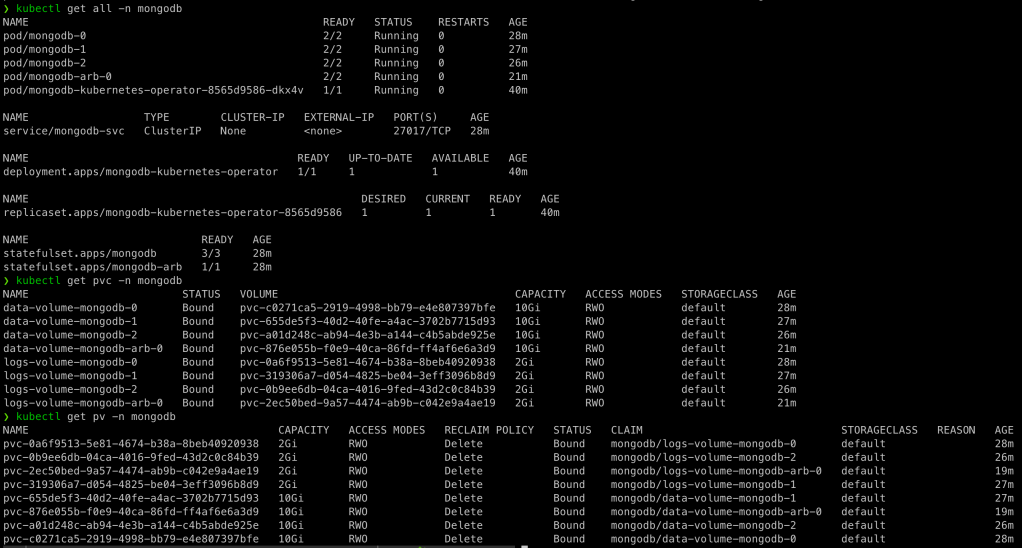
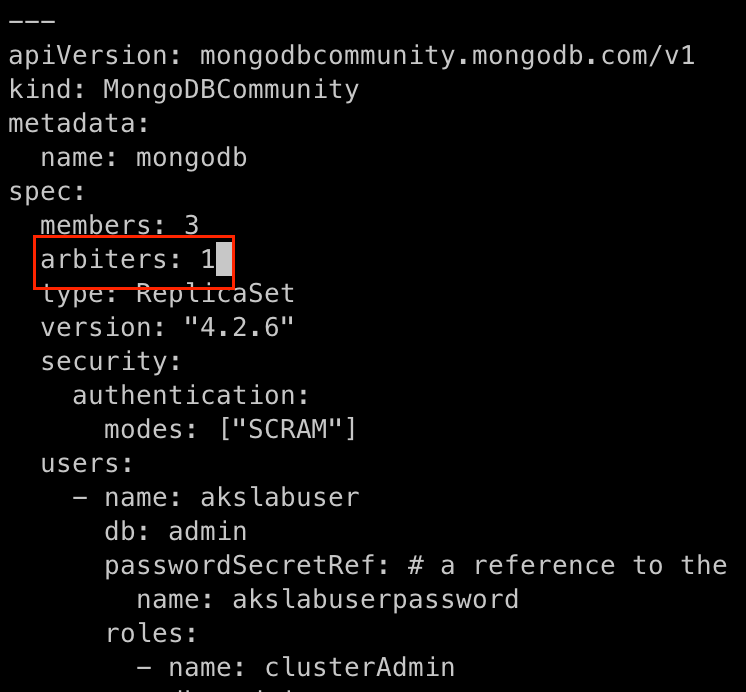
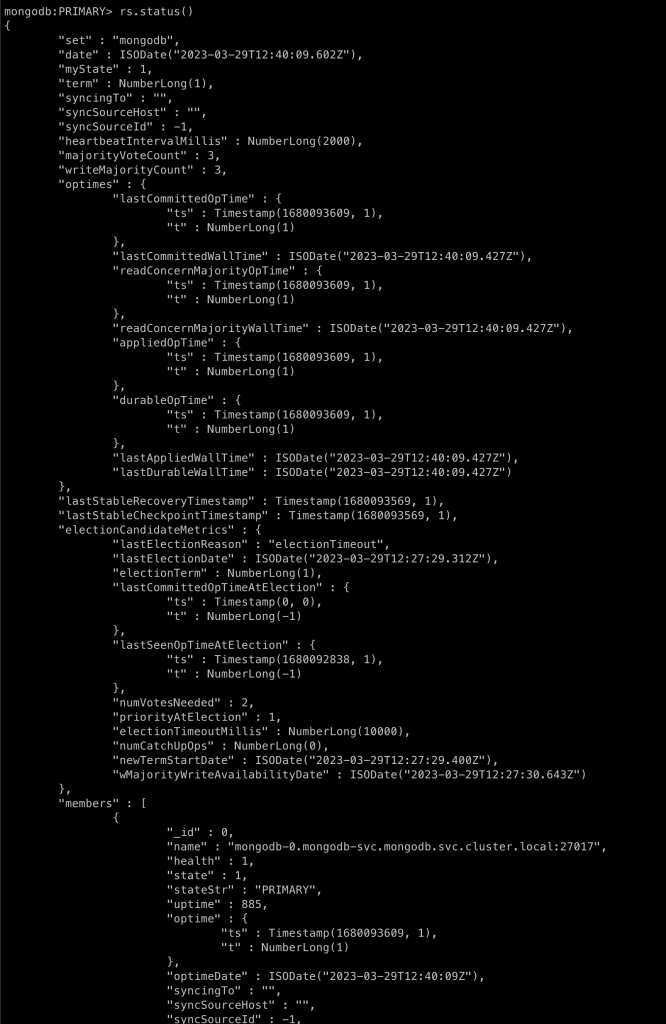
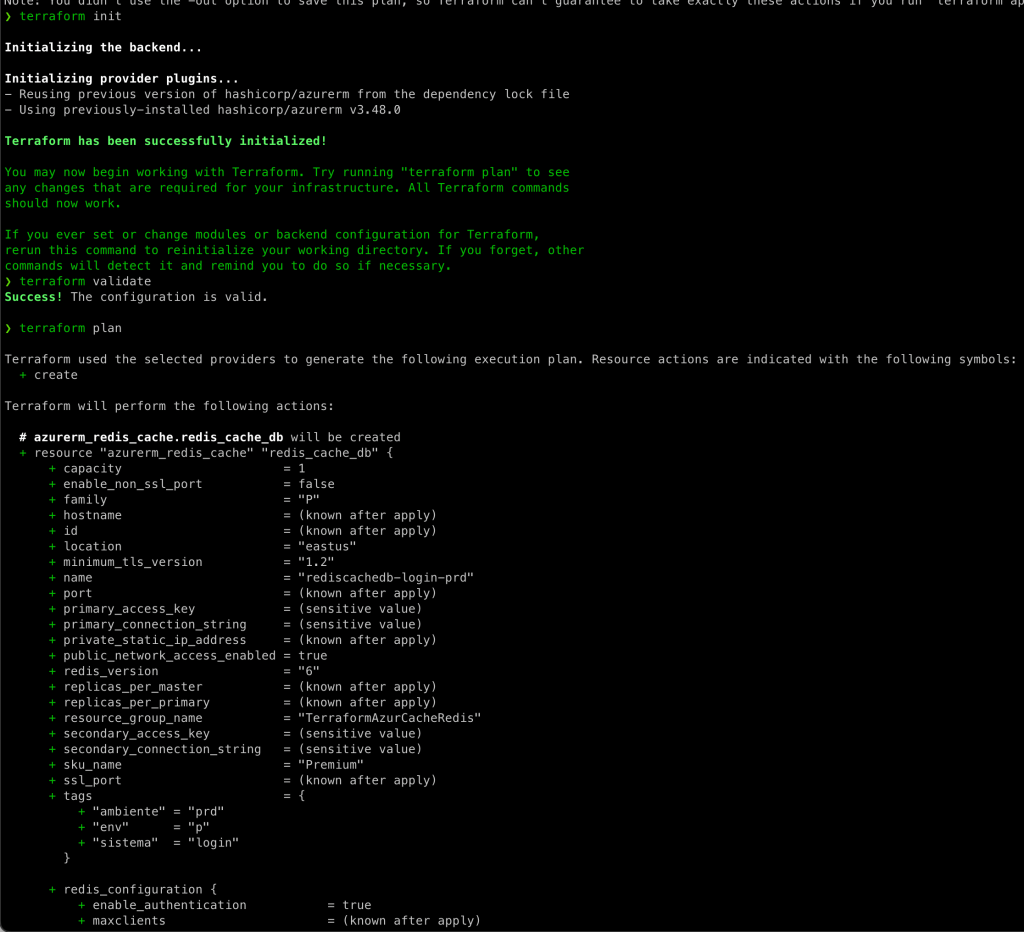
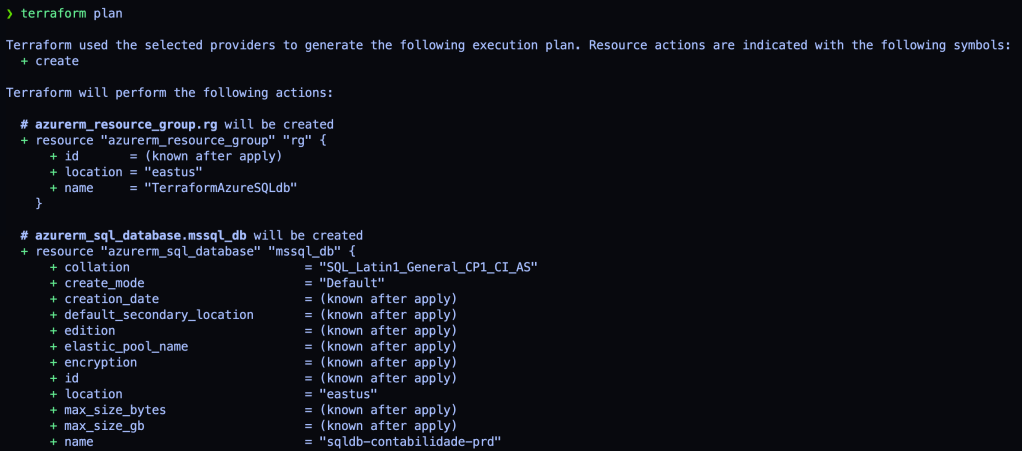
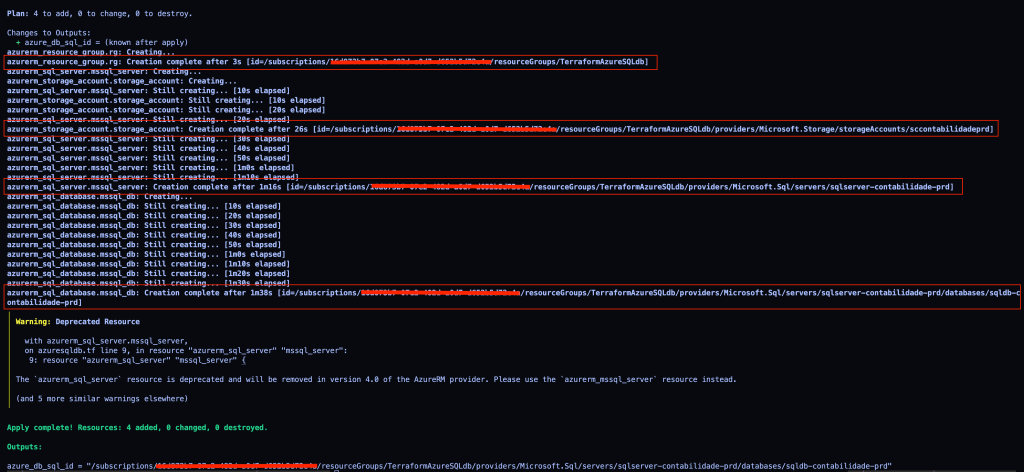
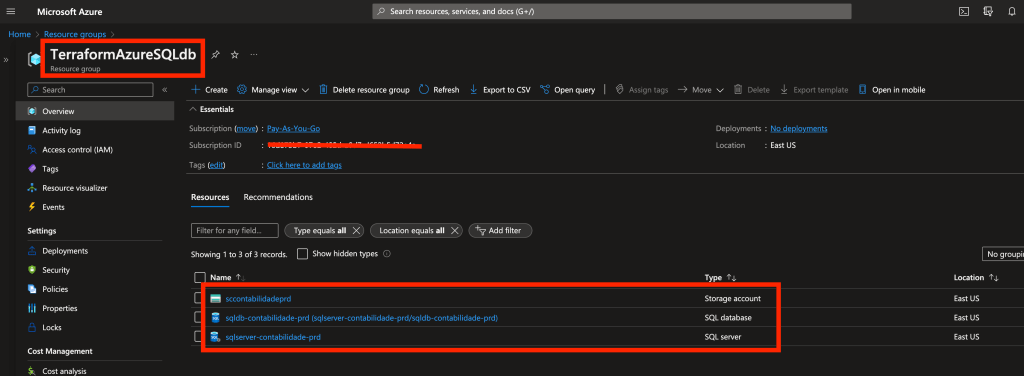
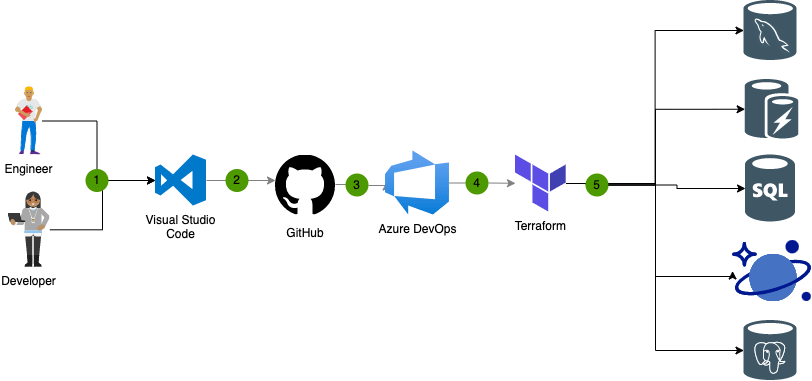
Fala galera!
Neste post veremos como é tranquilo provisionar uma instancia de banco de dados MySQL no Azure. Em breve devo fazer um post falando especificamente sobre o MySQL, neste caso iremos tratar apenas de como subir um novo cluster simples.
Acesse o o portal do Azure e busque por MySQL no campo de busca no canto superior central:
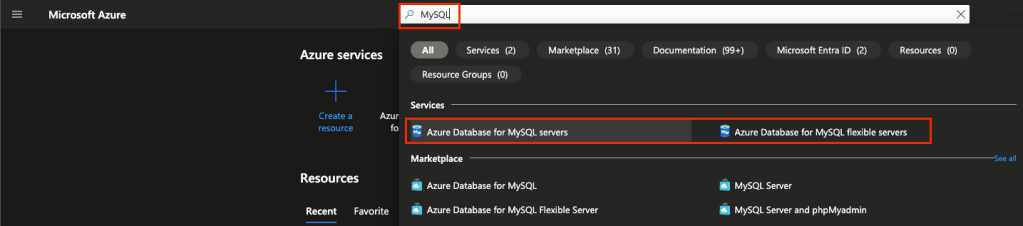
Como vocês podem ver, temos o Azure Database for MySQL severs e o flexible servers, já já vocês entenderão a diferença dos dois.
Clique em Create:

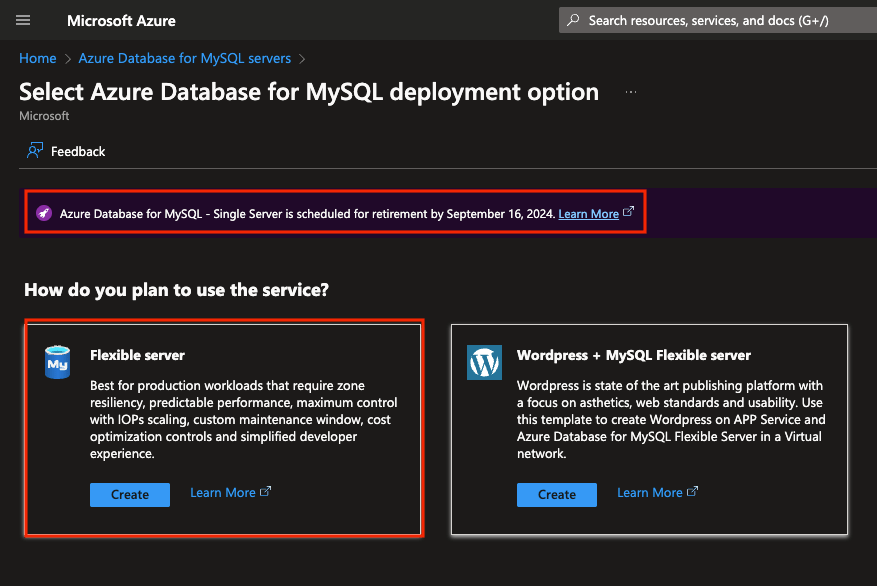
Agora podemos ver duas opções: Flexible server e WordPress + MySQL Flexible server. A primeira é o padrão e a indicada pelo Azure, a segunda é especifica para um provisionamento de um WordPress, desta forma ele provisiona a aplicação do WordPress no APP Service e já sobe uma instancia com o banco de dados no MySQL.
Podemos ver também que há uma mensagem onde o MySQL – Single Server esta sendo descontinuado e a Microsoft desaconselha utilizar este modelo, inclusive aconselha quem esteja o utilizando a migrar para o Flexible server, conforme esta documentação.
Clique em Create no Flexible server:
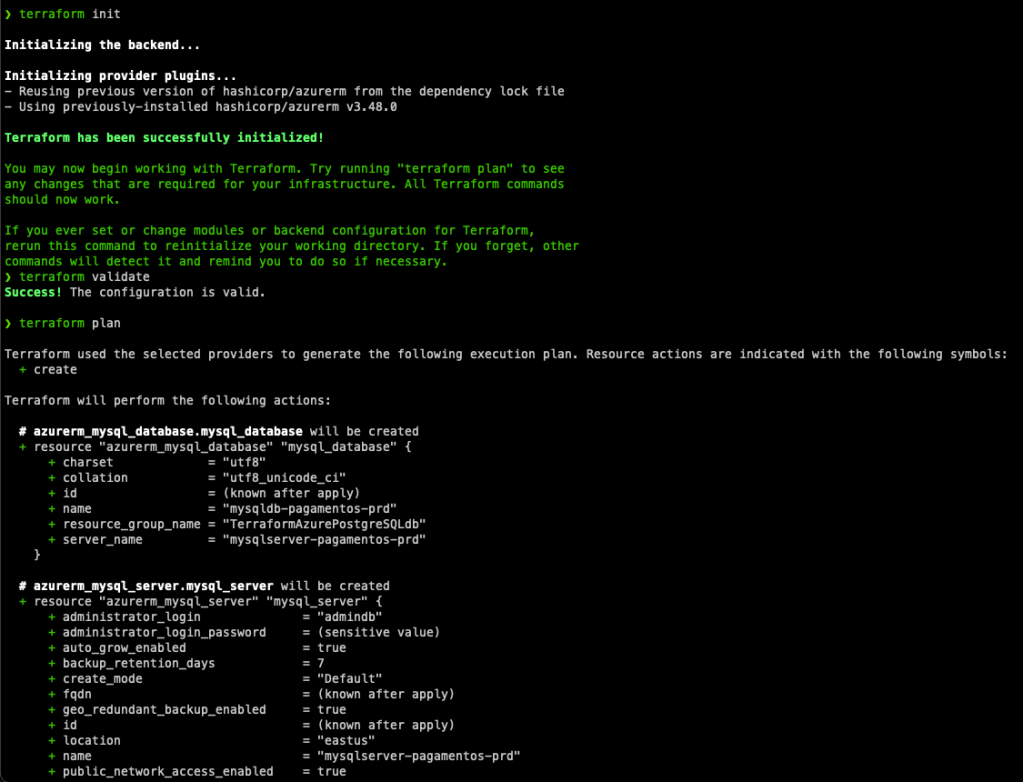
Na tela abaixo começaremos a configurar nosso cluster MySQL, escolha a Subscription e o Resource group. Depois coloque um nome que seja único para o cluster.
No campo MySQL version teremos a disposição as versões 5.7 e 8.0, sugiro sempre escolher a 8.0 que é a mais recente, a 5.7 esta em seu End Of Life, fora que a versão 8 tem muitas features interessantes.
No campo Workload type o Azure já te entrega algumas opções de pré configuração, setando um sizing adequado ao tipo de atividade ao qual seu ambiente irá rodar, isso já adianta a vida de quem tem duvidas de qual sizing aplicar. Ao lado direito você consegue conferir as configurações de Compute Size, Storage, IOPs, Backup e Bandwith\Rede tudo isso já com o custo estimado do ambiente:
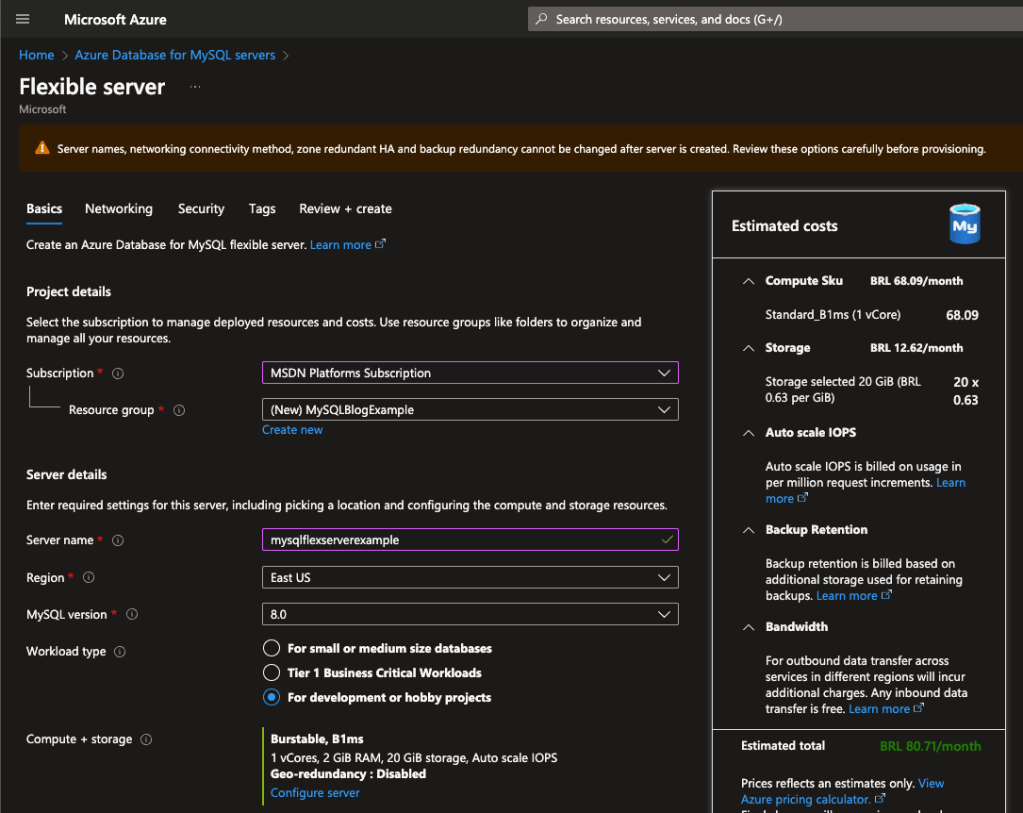
Caso você não queira trabalhar com essas sugestões, basta clicar em Compute + storage e configurar todos estes items dentro de suas necessidades:


Como é possível vermos acima temos 3 tipos de computação:
Burstable: opção mais barata de sizing entrega uma computação mais voltada para ambientes não produtivos como desenvolvimento e testes\qa;
General Purpose: este tipo entrega uma computação equilibrada entre vCPUs e memória RAM que atende o dia a dia da maioria das aplicações;
Business Critical: aqui temos sizings focados em processamento massivo de dados, entregando tamanhos grandes de instancias focados em aplicações que demandam muita CPU, memória RAM e máxima performance no acesso aos discos (iops).
A escolha do tamanho de maquina é o maior fator que pesará sobre o custo final, depois dela vem o Storage size juntamente com o número de operações de entrada e saída (iops). O custo de storage é de R$0,63 por GB enquanto a configuração de IOPS pode variar, se você escolher Auto scale IOPS será cobrado por uso em milhões de chamadas ou também é possível trabalhar com Pre-provisioned IOPS que é um valor máximo de operações de IO que a instancia poderá fazer entre leitura e escrita (recomendado), o custo por IOPs é de R$0,63 por IOPS.
As demais configurações são:
Storage Auto-Growth: crescimento automático do tamanho de storage disponível para o sgbd;
High Availability: nesta opção o Azure provisiona mais uma instancia para que haja uma contingência de ambiente e ai temos duas opções, colocar na mesma zona de disponibilidade ou em uma outra zona para termos redundância de sites;
Backup: aqui temos o tempo de retenção do backup da instancia que será executado automaticamente pelo serviço bem como se queremos torna-lo redundante não só na mesma avalability zone ou em outra para termos uma segurança a mais em caso de um disaster recovery.
Abaixo podemos ver uma configuração econômica para testes, configure e clique em Save:
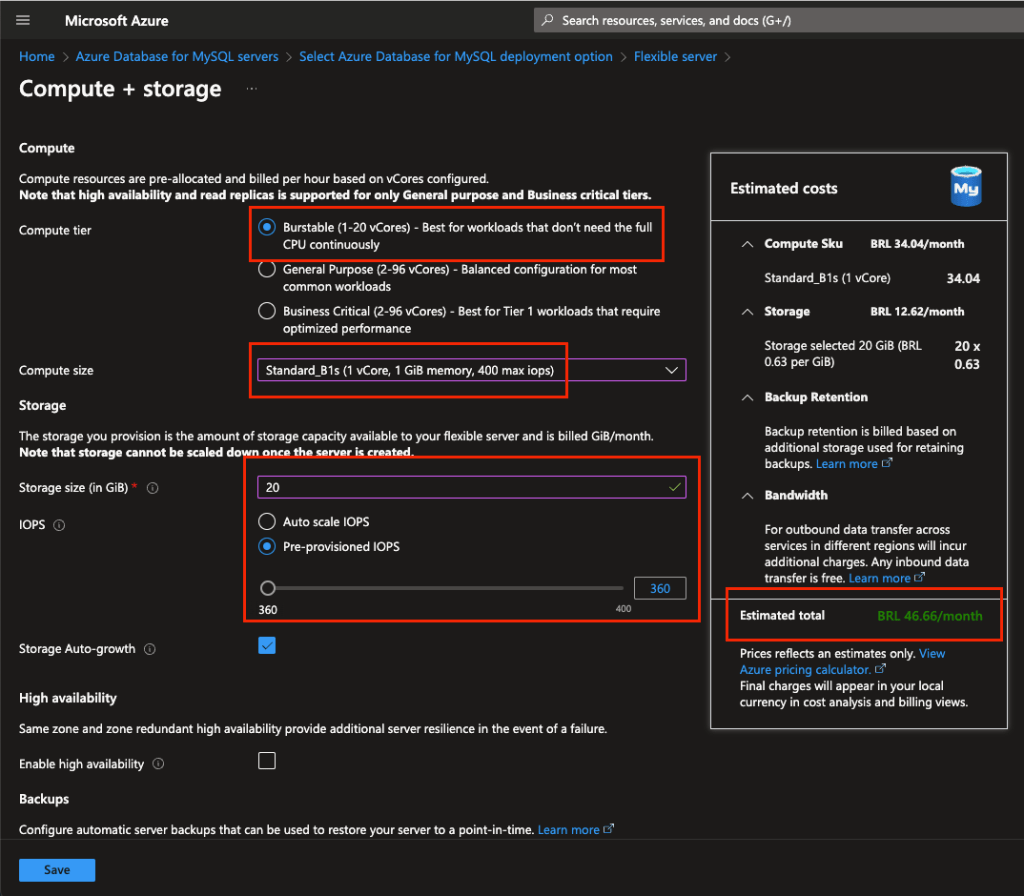
Abaixo voltamos para a primeira tela após escolher o sizing de nosso ambiente, podemos ver aqui também a opção de habilitarmos a alta disponibilidade do ambiente (HA) e também as configurações de autenticação, sendo estas:
MySQL auth only: aqui configuramos um usuário principal para a instancia, ele será o principal usuário a principio;
Microsoft Entra auth only: nesta configuração ativamos o Entra (Antigo Active Directory) que é o serviço de gestão de usuários da Microsoft;
MySQL and Microsoft Entra auth: aqui utilizaremos ambas as opções acima.
Para o nosso case vamos usar apenas o MySQL authentication, coloque um usuário e senha forte, depois clique em Next: Networking:
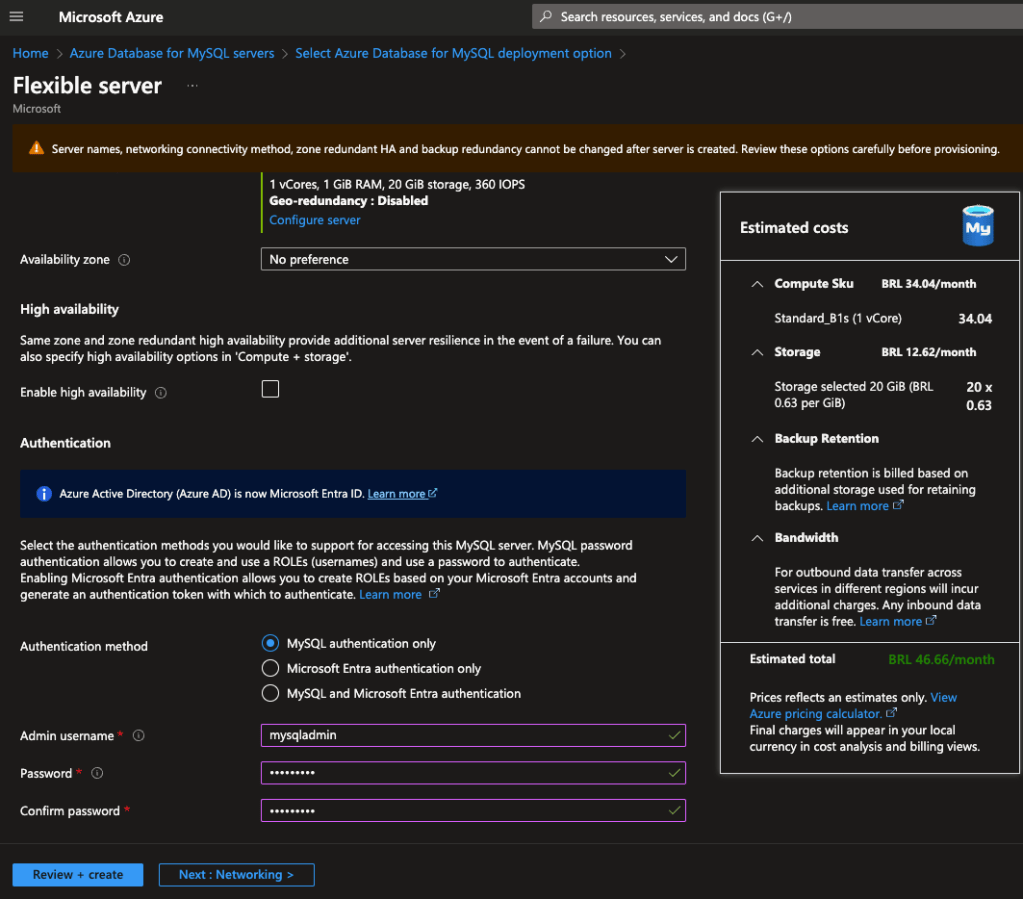
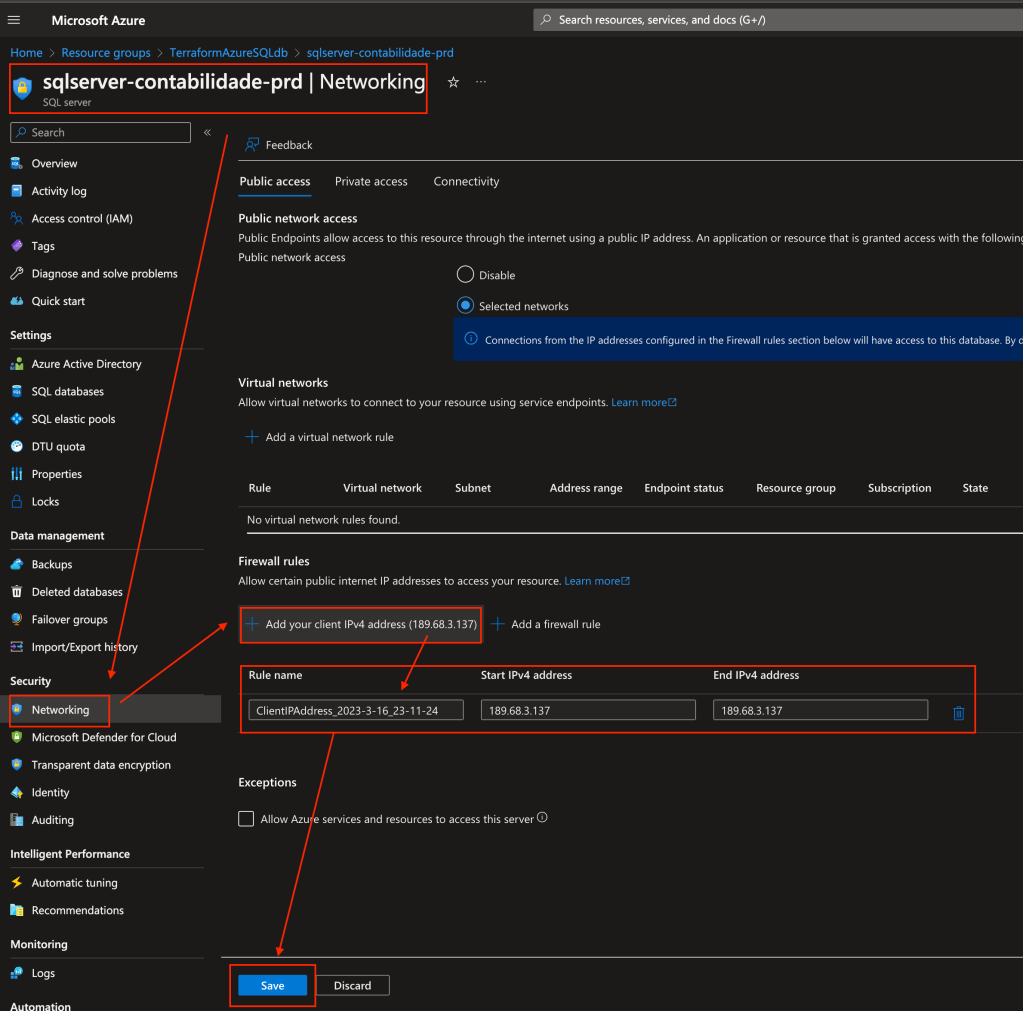
Na área de Networking veremos que podemos liberar o acesso publico que através do Firewall e via Private Endpoint ou apenas via Private access que depende de uma integração com a VNet. Para ambientes produtivos aconselho sempre trabalhar com Private Access por ser mais seguro, camadas de armazenamento de dados devem estar sempre restritas a aplicação que precisa acessa-las.
Para o nosso lab iremos utilizar o tipo de conectividade como Public access e também deixar marcado o check box de Public access para que possamos nos conectar nessa instancia de forma rápida.
Na parte de Firewall rules veremos um sinal de + um pouco abaixo, sugerindo a inclusão do nosso ip externo e para abrir para qualquer ip também, inclua ambos e clique depois em Next: security:
Aqui temos a configuração de criptografia em repouso (ou at rest), que é a criptografia em disco, onde nossos dados serão armazenados de forma segura a partir de uma chave de criptografia e autenticação segura, não ativaremos criptografia para este lab mas considere o fazer para ambientes produtivos. Clique em Review + create:
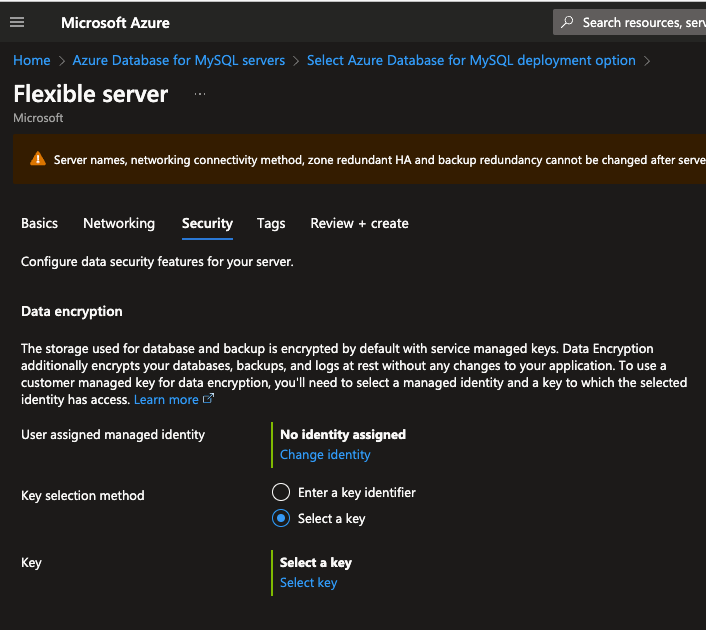
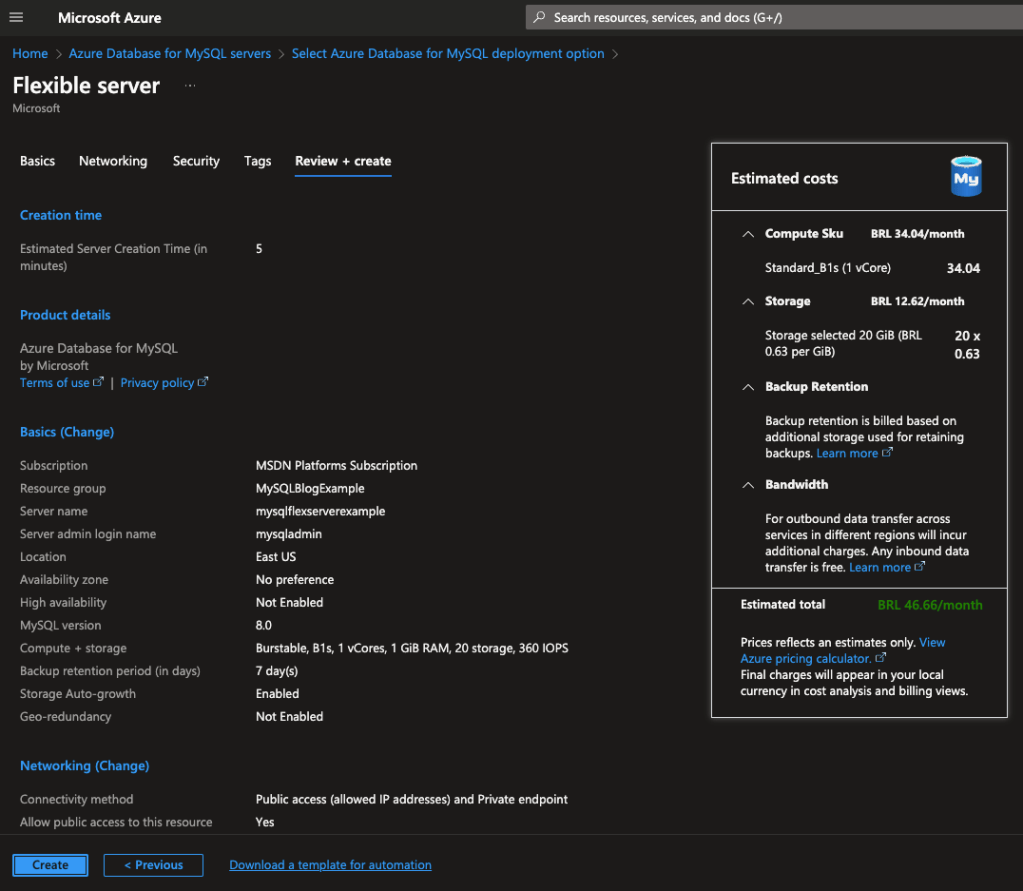
Após verificar o resumo sobre sua instancia, clique em Create:
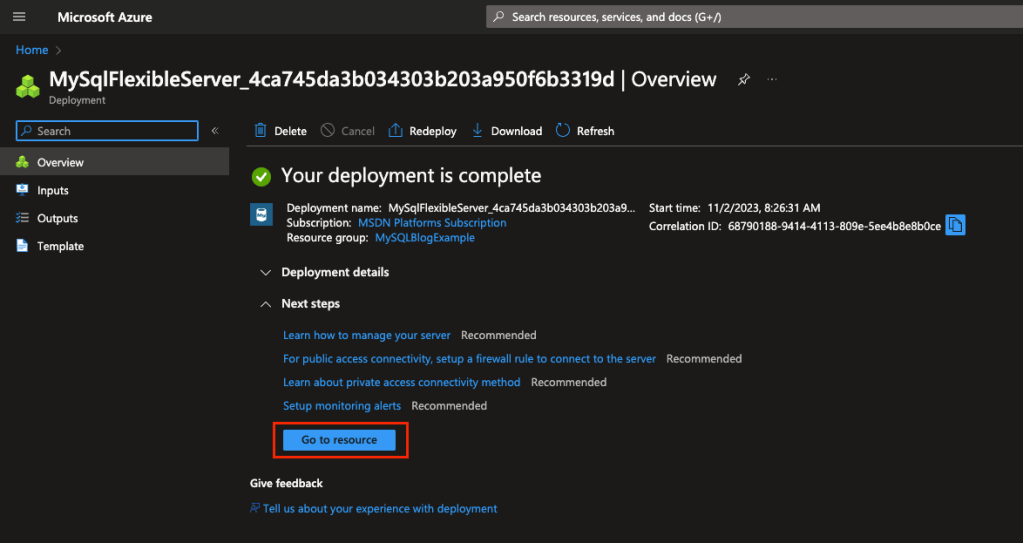
Depois de alguns minutos você terá sua instancia provisionada, clique no recurso para acessa-lo:
Este é o painel do Azure Database for MySQL flexible server, posteriormente farei outro post detalhando as opções, mas agora, vamos pegar o server name e o usuário para que possamos acessar nossa instancia:

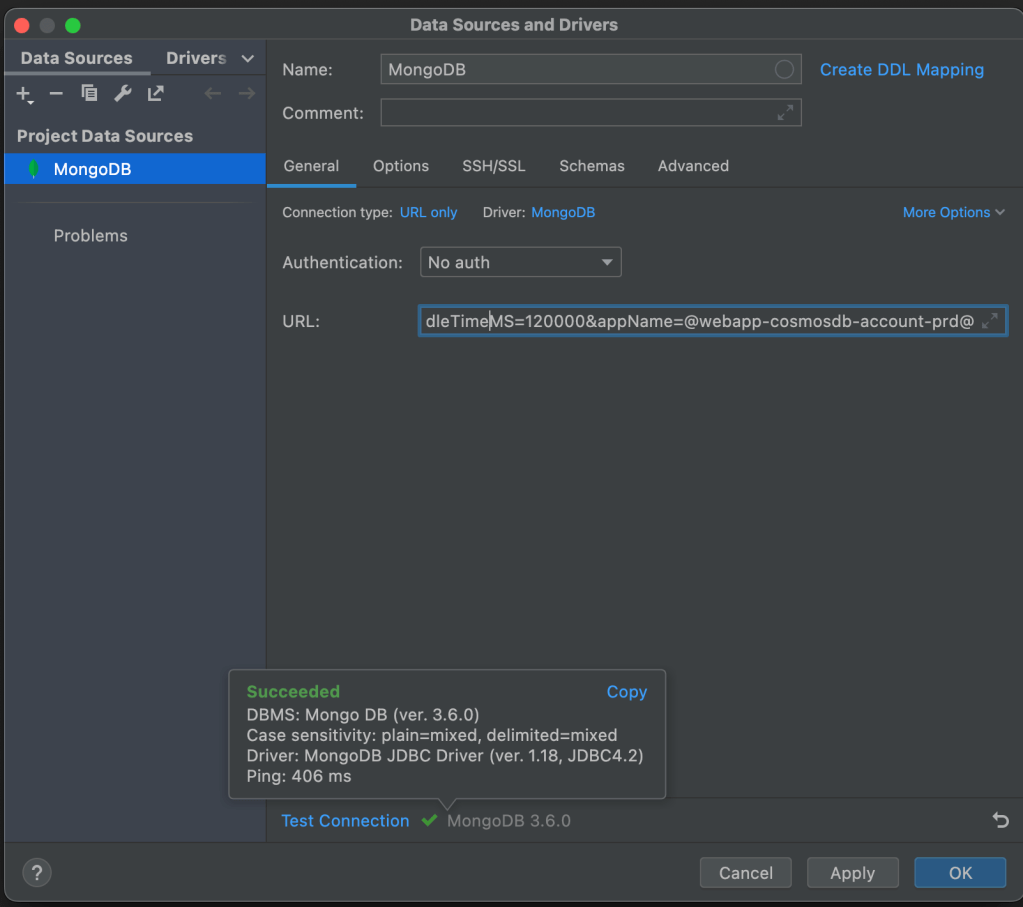
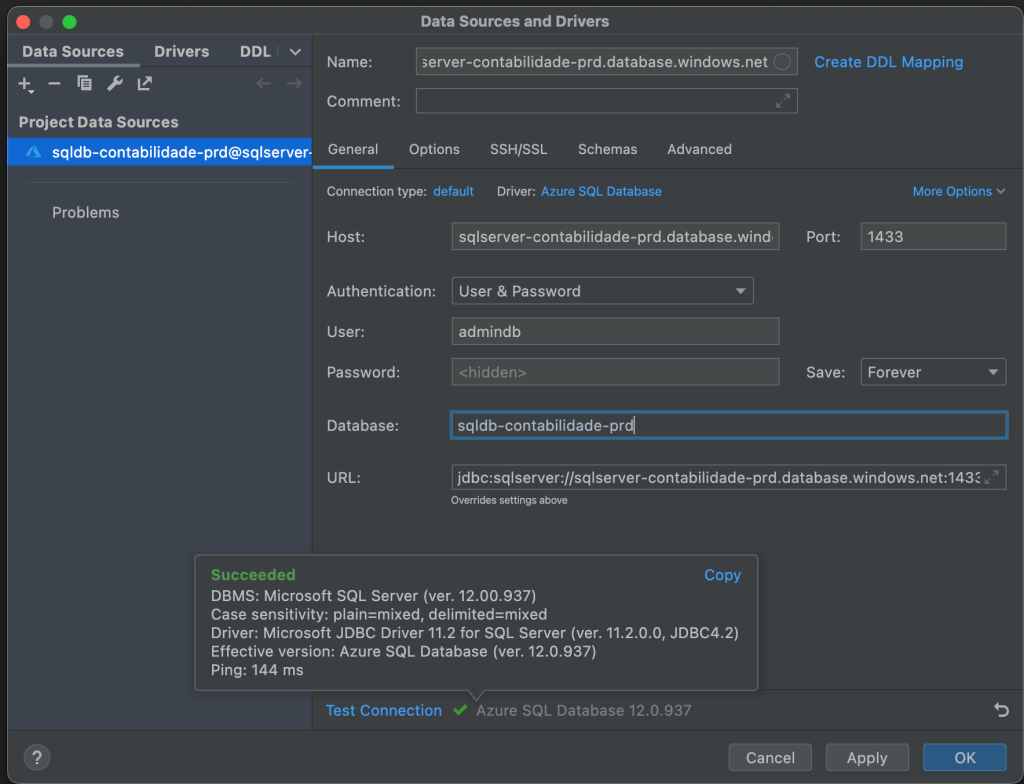
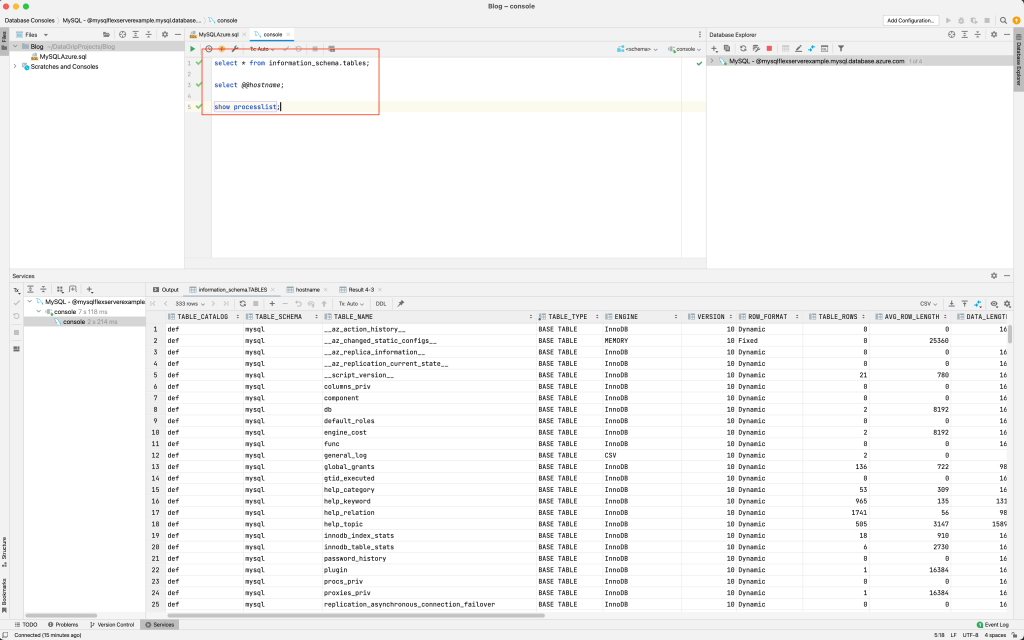
Estou utilizando o Jetbrains DataGrip, mas poderíamos estar utilizando o MySQL Workbench também, basta colocar o server name no campo Host e o usuário e senha e clicar em conectar:

Execute os SELECTs abaixo para que possamos ver as tabelas do sistema, o hostname e os processos em execução:
Para saber mais sobre o MySQL flexible servers consulte a documentação: https://learn.microsoft.com/en-us/azure/mysql/flexible-server/overview
É isso galera! Viram como é tranquilo criar uma instancia MySQL no Azure? Espero que tenham curtido. No próximo post veremos como criar uma instancia PostgreSQL gerenciada no Azure. Fiquem ligados!