
Fala galera!
Iniciando uma série aqui no Blog com o intuito de demonstrar como podemos utilizar o Kubernetes para executar bancos de dados, neste caso utilizaremos o serviço de Kubernetes gerenciado da Azure, o AKS – Azure Kubernetes Service para esta finalidade.
Bancos de dados, por característica, são aplicações stateful pois armazenam estado ou melhor, dados. Desde a versão 1.7 do Kubernetes temos a capacidade de provisionar StatefulSets que é uma feature muito parecida com o Deployment, porém, possui diferenças concideraveis como:
- O armazenamento de um determinado pod deve ser provisionado por um PersistentVolume Provisioner com base na classe de armazenamento solicitada ou pré-provisionado por um administrador.
- Excluir e/ou reduzir um StatefulSet não excluirá os volumes associados ao StatefulSet. Isso é feito para garantir a segurança dos dados, que geralmente é mais valioso do que uma limpeza automática de todos os recursos StatefulSet relacionados.
- Atualmente, os StatefulSets exigem que um Headless Service (também conhecido por Operator) seja responsável pela identidade de rede dos Pods. Você é responsável por criar este Serviço.
- Os StatefulSets não fornecem nenhuma garantia sobre o encerramento dos pods quando um StatefulSet é excluído. Para obter o encerramento ordenado e correto dos pods no StatefulSet, é possível reduzir o StatefulSet para 0 antes da exclusão.
- Ao utilizar Rolling Updates com a Pod Management Policy padrão (OrderedReady), é possível que o processo entre em um estado de falha que irá requerer intervenção manual para ser solucionado.
Para mais detalhes consultar a documentação pelo link: https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
Neste post iremos provisionar nosso cluster AKS deixando-o tudo preparado para seguir com o provisionamento das tecnologias de bancos de dados.
A ideia desta série será mostrar o provisionamento de bancos de dados relacionais (como o SQL Server 2022) e NoSQL demonstrando os detalhes de cada um e disponibilizando exemplos que poderão ser utilizados em seu ecosistema.
Antes de começar precisamos que o Azure CLI esteja instalado em seu sistema operacional para que possamos prosseguir: https://learn.microsoft.com/pt-br/cli/azure/install-azure-cli
No meu caso utilizo MacOS, basta executar o comando abaixo:
brew update && brew install azure-cli
Após ter o Azure CLI instalado, execute:
az login
Insira as informações de usuário e senha da sua conta e pronto, estará logado no Azure via CLI. Umas vez logado, execute o comando abaixo para criar um Resource Group o qual utilizaremos para provisionar nosso cluster AKS:
az group create --name lab_aks_databases --location eastus
Resource Group criado:
Podemos seguir para a criação do nosso cluster AKS:
az aks create -g lab_aks_databases -n aks_database_cluster --enable-managed-identity --node-count 3 --enable-addons monitoring --enable-msi-auth-for-monitoring --generate-ssh-keys
O cluster demora alguns minutos para ser provisionado, estamos criando um kubernetes com node-pool contendo 3 workers, desta forma podemos garantir uma alta disponibilidade de nossos ambientes de bancos de dados que irão ser provisionados neste ambiente.
Cluster criado:
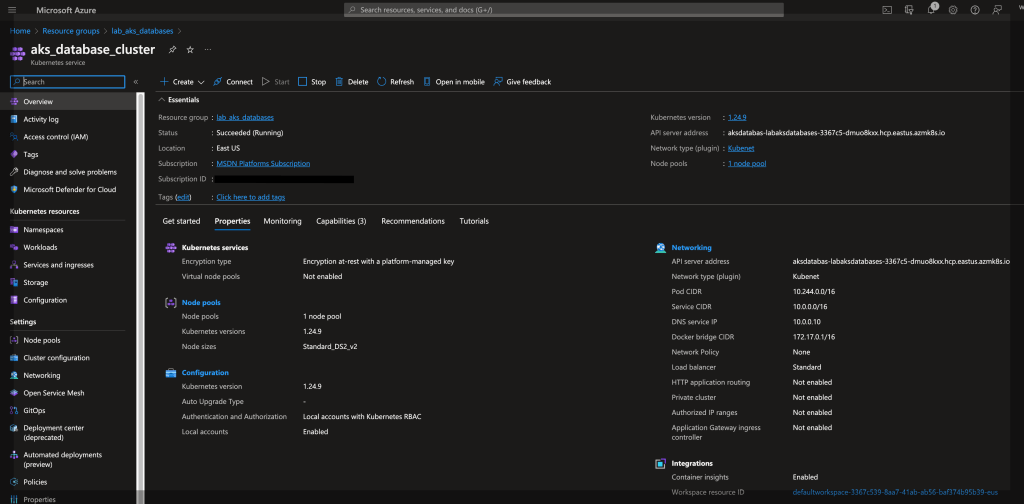
Após o cluster ficar disponível precisamos instalar o cli do aks pois precisamos do kubectl que é o CLI que iremos utilizar para interagir com nosso cluster AKS, para isso precisamos rodar o seguinte comando:
az aks install-cli
Depois de instalado precisamos baixar as credenciais para logar em nosso cluster, podemos fazer isso com o comando:
az aks get-credentials --resource-group lab_aks_databases --name aks_database_cluster

Este comando irá adicionar em nosso arquivo ~/.kube/config os certificados para que possamos conectar em nosso cluster:
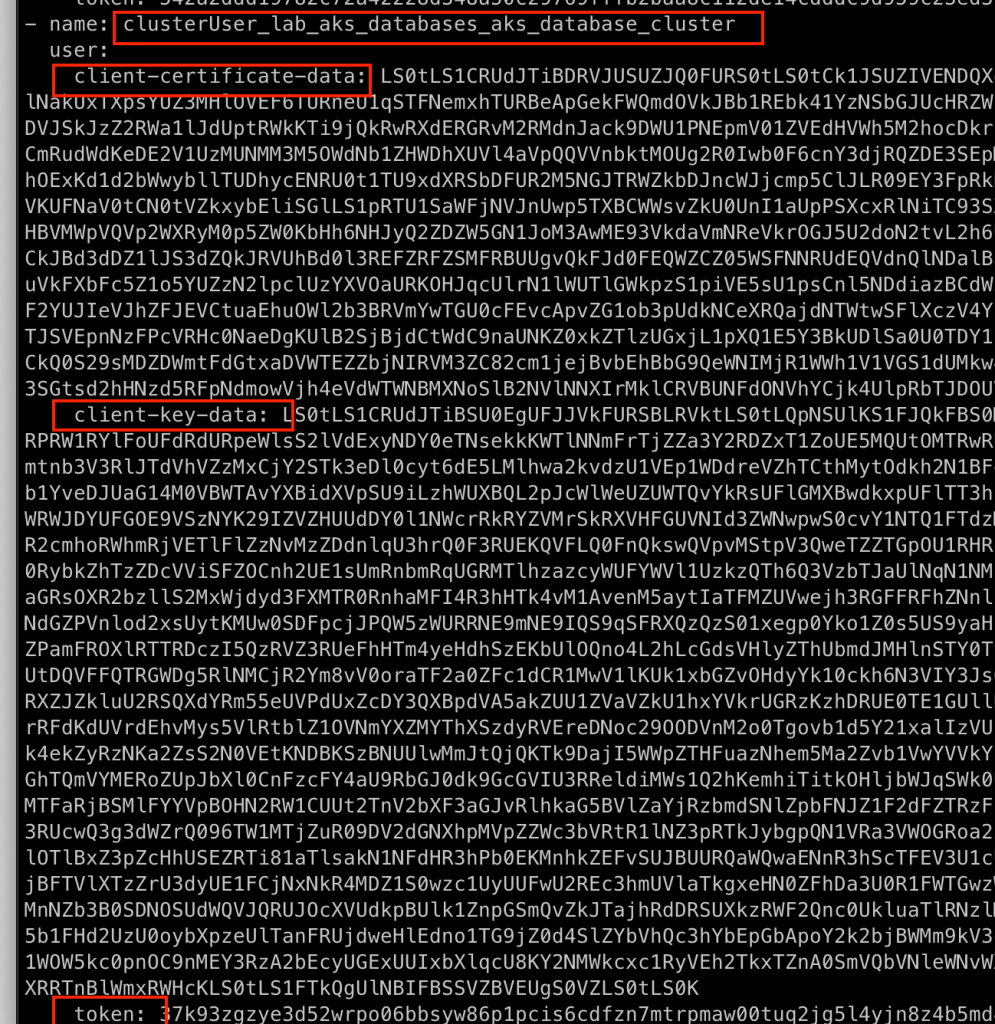
Assim que concluirmos essas configurações já podemos executar o comando kubectl para verificar se os nós de nosso cluster estão ok:
kubectl get nodes -o wide

Podemos conferir a mesma visão no console do Azure clicando na opção Node Pools:

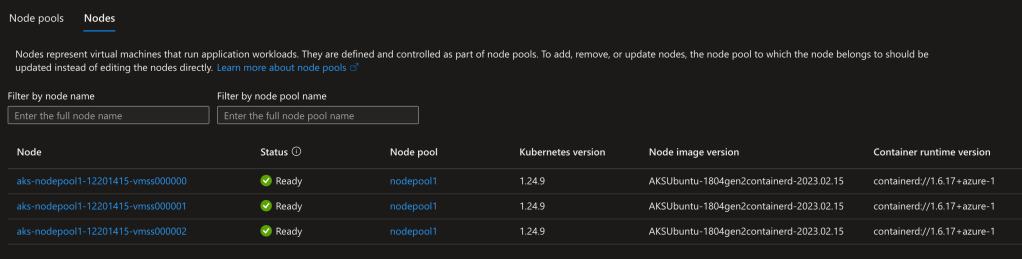
No próximo post iremos provisionar uma instancia SQL Server 2022 em nosso cluster, vocês verão como é simples disponibilizar bancos de dados no AKS!
Até a próxima gente!
