
Nos ultimos posts mostramos como subir um cluster AKS no Azure com extrema facilidade e também falamos sobre como funcionam o storage que será utilizado pelas instancias de bancos de dados, neste post iremos mostrar como executar uma instancia SQL Server 2022 neste nosso cluster AKS, vocês verão como é simples!
Para isolarmos o provisionamento de nossa instancia vamos criar um Namespace. O Namespace é uma forma de isolarmos as aplicações que estão criadas no kubernetes com o intuito de isolarmos projetos, times, empresas, entre outros.
Para criar um namespace executamos o comando:
kubectl create namespace sqlserver

Vamos agora criar um StorageClass definindo o tipo de disco do Azure que iremos utilizar em nossa instancia SQL Server, neste caso utilizaremos um disco Standard SSD com LRS (Local-Reduntant Storage), entregando 11 9’s de disponibilidade garantindo cópias locais deste disco. Para saber quais são os outros tipos de discos consulte o link: https://learn.microsoft.com/en-us/azure/virtual-machines/disks-types
Neste caso estamos utilizando um disco Standard pois estamos em um ambiente controlado, caso esteja indo para produção e considere que seu sistema irá utilizar IO de forma intensiva com alto throughput então considere utilizar um tipo de storage Premium.
Continuando com o provisionamento, vamos criar uma pasta para jogarmos nosso projeto:
mkdir k8smssql
cd k8smssql
Crie um arquivo sc.yaml contendo a especificação de criação de seu StorageClass:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azure-disk
provisioner: kubernetes.io/azure-disk
parameters:
storageaccounttype: Standard_LRS
kind: Managed
Agora vamos criar o PersistentVolumeClaim que é a requisição por um storage, este componente requisita um storage baseado em um StorageClass, volumetria bem determinada e qual será o tipo acesso que os Pods poderão fazer ao storage solicitado, no caso abaixo utilizaremos ReadWriteOnce onde apenas o Pod o qual o storage for alocado poderá ler e escrever deste. Crie um arquivo pvc.yaml:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mssql-data
annotations:
volume.beta.kubernetes.io/storage-class: azure-disk
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Após criar os arquivos, vamos executa-los com os comandos abaixo, no caso PVC vamos coloca-lo em nosso namespace:
kubectl create -f sc.yaml
kubectl create -f pvc.yaml -n sqlserver

Para listar os recursos criados, basta executar os comandos abaixo:
kubectl get storageclass
kubectl get pvc -n sqlserver

Como podemos ver, existem diversos tipos de StorageClass que já explicamos no post anterior, destacados estão os que acabamos de criar.
Já que fizemos uma requisição por um volume via um Persistent Volume Claim e declaramos um storage gerenciado em Cloud, podemos ver que um volume já foi criado a partir desta requisição, que podemos conferir executando:
kubectl get pv -n sqlserver

Agora que já temos um volume, vamos criar um Secret aonde iremos armazenar a senha do nosso querido usuário SA da nossa instancia SQL Server:
kubectl create secret generic mssql --from-literal=MSSQL_SA_PASSWORD="MSSQL@k8sp@ssw0rd" -n sqlserver

Agora vamos criar nosso Deployment que disponibilizará uma instancia SQL Server 2022 utilizando nosso Persistent Volume e Secret já criados. Crie um arquivo mssql.yaml e insira o conteúdo abaixo:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mssql-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mssql
template:
metadata:
labels:
app: mssql
spec:
terminationGracePeriodSeconds: 30
hostname: mssqlinst
securityContext:
fsGroup: 10001
containers:
- name: mssql
image: mcr.microsoft.com/mssql/server:2022-latest
resources:
requests:
memory: "4G"
cpu: "2000m"
limits:
memory: "4G"
cpu: "2000m"
ports:
- containerPort: 1433
env:
- name: MSSQL_PID
value: "Developer"
- name: ACCEPT_EULA
value: "Y"
- name: MSSQL_SA_PASSWORD
valueFrom:
secretKeyRef:
name: mssql
key: MSSQL_SA_PASSWORD
volumeMounts:
- name: mssqldb
mountPath: /var/opt/mssql
volumes:
- name: mssqldb
persistentVolumeClaim:
claimName: mssql-data
Questões importantes que podemos destacar do yaml acima:
- Estamos criando um Deployment e não um StatefulSet por que neste caso utilizaremos uma instancia Standalone e não em FCI – Failover Cluster Instance ou AlwaysOn Availability Groups, logo, não precisamos de um Operator para gerenciar o estado deste cluster, tornando a infra mais simples;
- Estamos solicitando um pod com 2 vCPU’s e 4GB de RAM;
- A versão que estamos subindo é a Developer.
Para criar basta executar o comando abaixo, depois vamos listar os pods:
kubectl create -f mssql.yaml -n sqlserver
kubectl get pod -n sqlserver

Podemos ver que o Pod com o SQL Server foi criado, mas o status fica em Pending, a instancia não entra em execução, vamos investigar:
kubectl describe pod mssql-deployment-69cf4fff84-hr2w8 -n sqlserver
No final da saída do comando Describe podemos ver que não temos recursos o suficiente para executar nosso banco de dados, neste caso CPU e memória:

Sendo assim, como não podemos escalar verticalmente nossos workers do node pool que já existe, teremos que criar um novo node pool com instancias do tamanho que precisamos e o kube-scheduler se incumbira de criar o pod neste node pool uma vez que há recursos o suficiente lá:
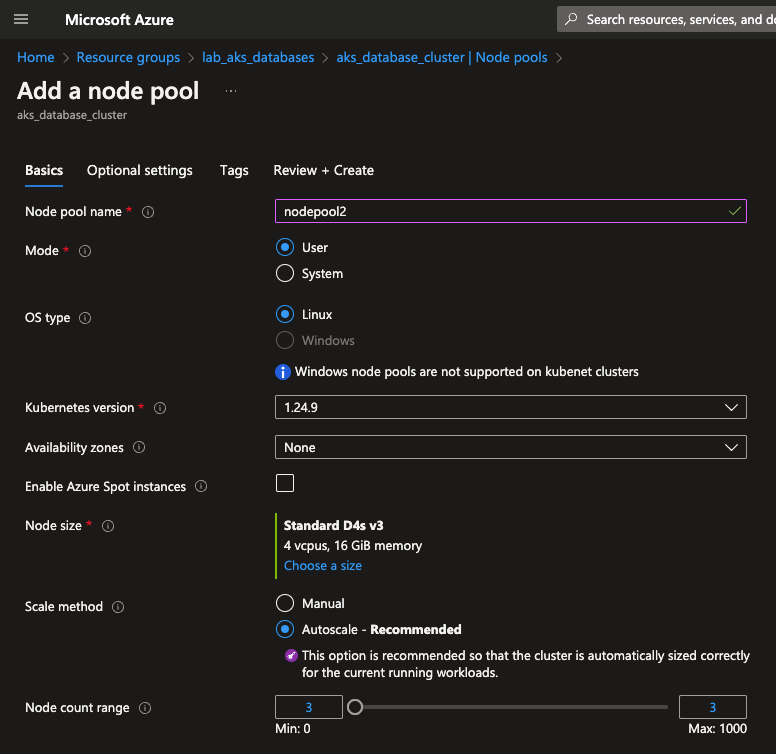

Agora vamos deletar nosso Deployment e criar novamente:
kubectl delete -f mssql.yaml -n sqlserver
kubectl create -f mssql.yaml -n sqlserver
Depois disso vamos verificar se nosso Pod irá subir:

Percebi que estava demorando muito para criar, então fui investigar:
kubectl describe pod mssql-deployment-69cf4fff84-fbsbz -n sqlserver
E novamente temos um problema, porém agora no Persistent Volume que já havia sido alocado para outro Pod:

Para garantir, vamos apagar nosso Deployment e PVC e criar novamente
kubectl delete -f mssql.yaml -n sqlserver
kubectl delete -f pvc.yaml -n sqlserver
kubectl create -f pvc.yaml -n sqlserver
kubectl create -f mssql.yaml -n sqlserver
Agora sim! Nosso pod foi provisionado com sucesso:
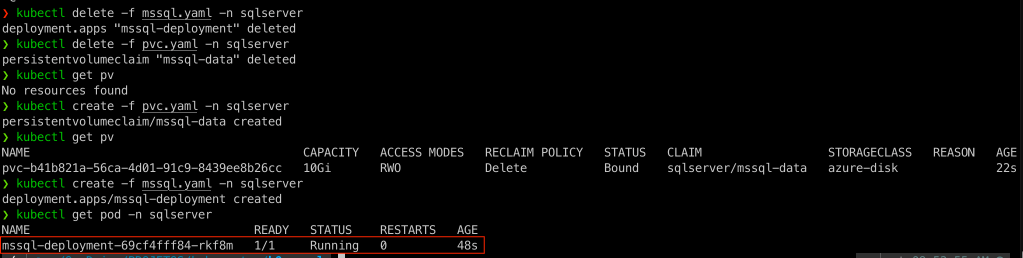
Para verificar em qual node ele foi provisionado podemos executar um Describe ou listar com a opção -o wide:
kubectl get pod -n sqlserver -o wide
Como podemos ver ele foi alocado no Node Pool 2 que acabamos de criar:

Agora precisamos criar um Service para que possamos chegar na instancia provisionada, para isso crie um arquivo service.yaml com o conteúdo:
apiVersion: v1
kind: Service
metadata:
name: mssql-deployment
spec:
selector:
app: mssql
ports:
- protocol: TCP
port: 1433
targetPort: 1433
type: LoadBalancer
Podemos ver que o tipo de Service é LoadBalancer, isso por que estamos em uma cloud e a mesma disponibiliza este tipo de recurso que podemos utilizar para ganhar um IP Externo para que possamos conectar em nosso recurso.
kubectl create -f service.yaml -n sqlserver
kubectl get service -n sqlserver

Agora basta conectarmos em nossa instancia :
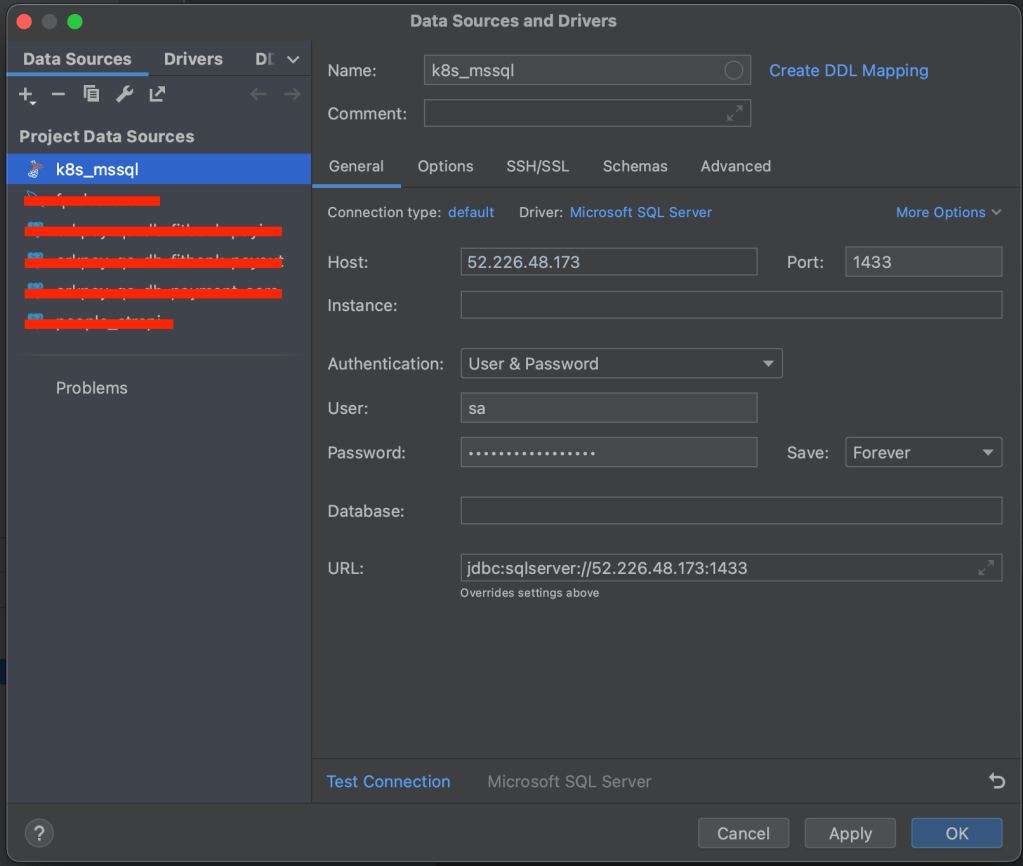
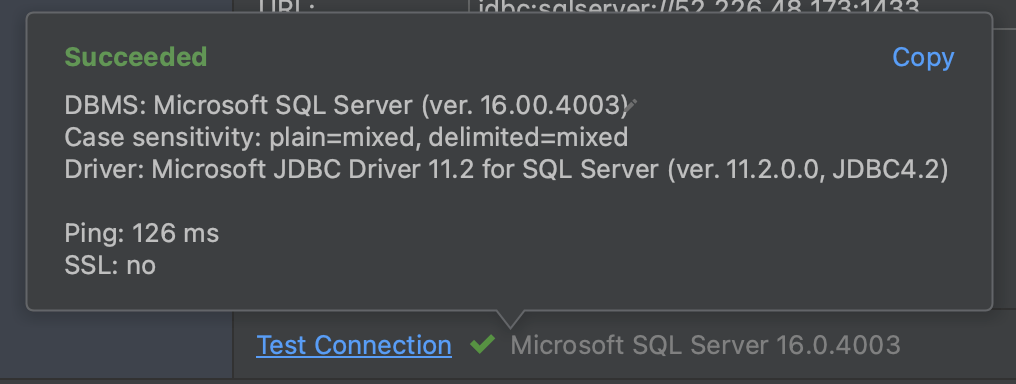
Após conectar execute os comandos abaixo para verificarmos a versão de nosso SQL Server e o nome do hostname:
SELECT @@version;
SELECT @@servername;

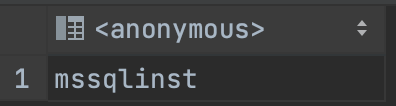
Como podemos ver estamos executando nosso Pod com SQL Server 2022 Developer em uma imagem Ubuntu 20.04 e o nome da instancia é o mesmo declarado em nosso deployment, este é o hostname do container que esta executando nosso SQL Server.
Vamos criar um banco de dados, uma tabela neste banco e alguns registros para verificar a persistencia:
CREATE DATABASE k8sdb;
USE k8sdb;
CREATE TABLE exemplo(
id int identity primary key
, nome varchar(1000)
, dtnasc date
);
INSERT INTO exemplo(nome, dtnasc) VALUES ('Maria','1958-01-23'),( 'João', '1990-05-01');
SELECT * FROM exemplo;
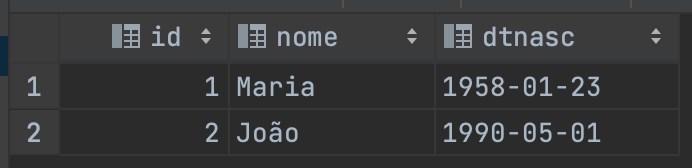
É isso gente, neste post vimos como provisionar uma instancia SQL Server e só não foi mais simples por que tivemos alguns problemas por conta de limitações de hardware do nosso cluster, porém, vimos como fazer o troubleshooting deste tipo de problema e como é simples contorna-lo graças a estamos utilizando o AKS!
Nosso projeto para subir um SQL Server 2022 no k8s ficou assim:
E nosso cluster AKS ganhou novos recursos que podemos ver no Resource Group de apoio, agora temos Load Balancer, Volumes, Node Pool novo e um Public IP:

Para limpar nosso ambiente basta executar o delete de cada recurso criado, mas como colocamos tudo dentro de um namespace, podemos excluir o namespace todo:
kubectl delete namespace sqlserver
É isso por hoje gente, no próximo post veremos como subir um cluster de Redis no nosso AKS, muito obrigado pela atenção!
