
Continuando nossa série de bancos de dados executando no AKS, no ultimo episódio provisionamos nosso querido e amado SQL Server 2022 em container rodando no Kubernetes com Azure Standard SSD.
Desta vez vamos mostrar como subir um cluster do banco de dados Chave-Valor mais utilizado no mercado e que ainda entrega uma capacidade de Caching de dados por conta da sua engine In-Memory, este é o Redis.
Por característica, bancos de dados voltados para Caching de dados tem o intuito de retirar carga de leitura intensa de bancos de dados relacionais ficando entre a camada de aplicação e o banco de dados tradicional. Isso acontece por conta da engine In-Memory deste banco de dados NoSQL key-valued store que trabalha na escala de nano\micro segundo uma vez que os dados ficam fixados na RAM dos servidores e por sua capacidade de escalabilidade horizontal, que por sua vez, pode entregar cada vez mais capacidade de leitura intensa no menor tempo possível para aplicação.
Para este laboratório me baseei em duas documentações:
- Deploying Redis Cluster on Kubernetes | Tutorial and Examples –
Bharathiraja Shanmugam - Deploy Redis Enterprise Software for Kubernetes – Original Redis
O Redis, por padrão, é provisionado em cluster com no mínimo 3 nodes, sendo assim, vamos começar criando nosso famigerado Namespace:
kubectl create namespace redis
Uma vez criado nosso ns agora vamos criar um ConfigMap que será utilizado como base de configuração para nossos Pods Redis. Crie um arquivo configmap.yaml com o conteúdo a seguir:
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-config
data:
redis.conf: |
masterauth R3d!s@2023
requirepass R3d!s@2023
bind 0.0.0.0
protected-mode no
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize no
supervised no
pidfile "/var/run/redis_6379.pid"
loglevel notice
logfile ""
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename "dump.rdb"
rdb-del-sync-files no
dir "/data"
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-diskless-load disabled
repl-disable-tcp-nodelay no
replica-priority 100
acllog-max-len 128
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
lazyfree-lazy-user-del no
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4kb
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
jemalloc-bg-thread yes
Caso queira saber mais sobre as opções utilizadas, verificar o arquivo de configuração completo em: https://redis.io/docs/management/config-file/
kubectl create -f configmap.yaml -n redis

Agora vamos criar no primeiro StatefulSet, quem leu os posts anteriores verificou que o Kubernetes é primeiramente voltado a execução de containers em Pods que por característica beneficiam aplicações Stateless, ou seja, que não armazenam estado, porém, com o advento e amadurecimento da orquestração de containers no K8s surgiu este recurso que nos auxilia a provisionar cluster de sistemas que precisam armazenar dados.
Crie um arquivo redis-cluster.yaml com o conteúdo:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis
spec:
serviceName: redis
replicas: 3
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
initContainers:
- name: config
image: redis:6.2.3-alpine
command: [ "sh", "-c" ]
args:
- |
cp /tmp/redis/redis.conf /etc/redis/redis.conf
echo "finding master..."
MASTER_FDQN=`hostname -f | sed -e 's/redis-[0-9]\./redis-0./'`
if [ "$(redis-cli -h sentinel -p 5000 ping)" != "PONG" ]; then
echo "master not found, defaulting to redis-0"
if [ "$(hostname)" == "redis-0" ]; then
echo "this is redis-0, not updating config..."
else
echo "updating redis.conf..."
echo "slaveof $MASTER_FDQN 6379" >> /etc/redis/redis.conf
fi
else
echo "sentinel found, finding master"
MASTER="$(redis-cli -h sentinel -p 5000 sentinel get-master-addr-by-name mymaster | grep -E '(^redis-\d{1,})|([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3})')"
echo "master found : $MASTER, updating redis.conf"
echo "slaveof $MASTER 6379" >> /etc/redis/redis.conf
fi
volumeMounts:
- name: redis-config
mountPath: /etc/redis/
- name: config
mountPath: /tmp/redis/
containers:
- name: redis
image: redis:6.2.3-alpine
command: ["redis-server"]
args: ["/etc/redis/redis.conf"]
ports:
- containerPort: 6379
name: redis
volumeMounts:
- name: data
mountPath: /data
- name: redis-config
mountPath: /etc/redis/
volumes:
- name: redis-config
emptyDir: {}
- name: config
configMap:
name: redis-config
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-csi"
resources:
requests:
storage: 500Mi
Destaque para o storageClassName onde utilizaremos um Azure Standard SSD em modo de acesso ReadWriteOnce, necessário para este tipo de implementação. Podemos destacar também que estamos subindo 3 replicas de instancias Redis versão 6.2.3 em imagem alpine (uma das mais leves, pesando apenas alguns megabytes), porta interna default 6379 e com o nosso configmap apontado.
Execute a criação dos componentes:
kubectl create -f redis-cluster.yaml -n redis
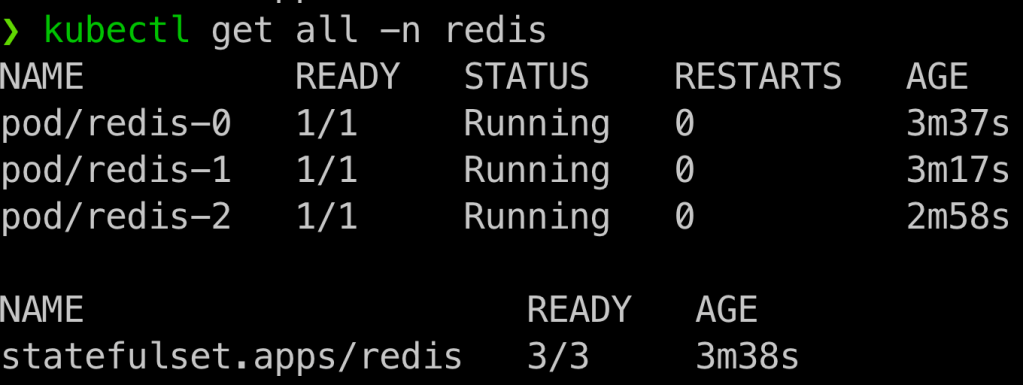
Verifique se tudo foi criado com êxito:
kubectl get all -n redis
kubectl get pv -n redis
kubectl get pvc -n redis

Se executarmos um describe no StatefulSet para verificar mais detalhes do provisionamento podemos ver que tudo foi executado com sucesso:
kubectl describe statefulset redis -n redis

Agora que temos nosso cluster no ar, vamos criar o Service necessário para que possamos acessar a instancia Redis, crie um arquivo svc.yaml com:
apiVersion: v1
kind: Service
metadata:
name: redis
spec:
type: LoadBalancer
ports:
- port: 6379
targetPort: 6379
name: redis
selector:
app: redis
Agora execute:
kubectl create -f svc.yaml -n redis
kubectl get service -n redis

Vamos verificar se esta tudo certo com a replicação do nosso cluster Redis? Para isso vamos verificar o Log interno de um dos Pods de nosso cluster para verificar se esta tudo funcionando conforme esperado:
kubectl logs redis-1 -n redis | tail -30
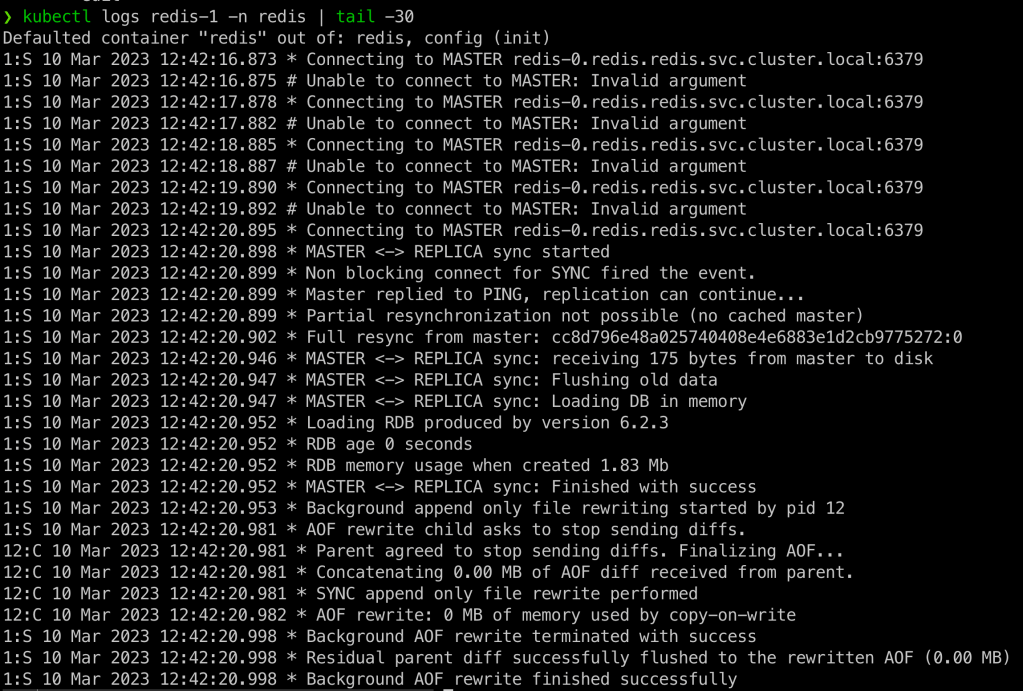
Podemos verificar as ultimas 30 linhas do log da instancia redis-1 que ela ficou um tempo tentando se conectar com a instancia PRIMARIA redis-0 e uma vez que conseguiu houve uma sincronização quase instantânea. Olhando para o node redis-0 podemos verificar que tudo esta funcionando apropriadamente também:
kubectl logs redis-0 -n redis
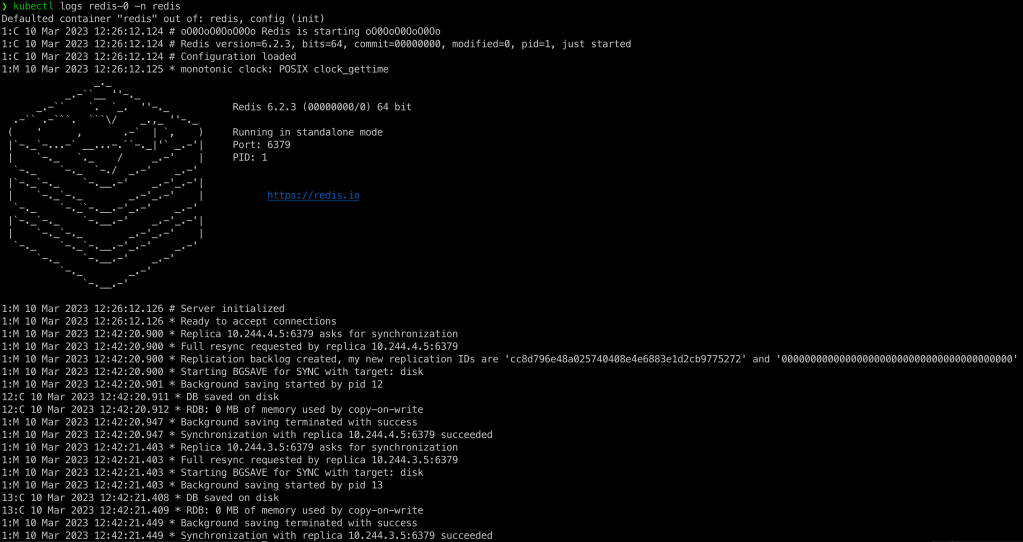
Vamos agora nos conectar na instancia redis-0 e executar alguns comandos no Redis para verificar mais informações:
kubectl -n redis exec -it redis-0 -- redis-cli
auth R3d!s@2023 #senha definida no ConfigMap
info replication

Apenas para validar se a replicação esta de fato funcionando apropriadamente, vamos criar alguns registros no banco de dados para verificar se replicação acontecerá para as replicas:
SET key0 value0
SET key1 value1
SET key2 value2
SET key3 value3
SET key4 value4
KEYS *
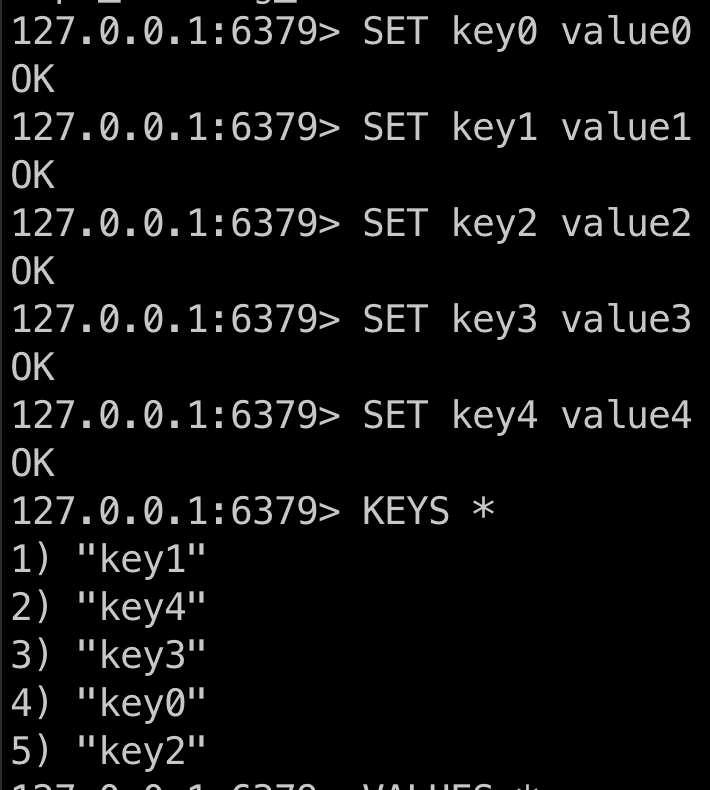
Para verificar os valores:
GET key0
GET key1
GET key2
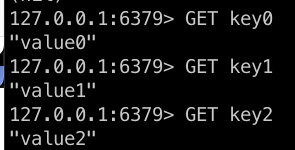
Como podemos confirmar, o Redis é um banco de dados muito simples, cumprindo o papel de ser rápido e eficiente para cache.
Vamos agora para outra replica verificar se os dados estão la:
kubectl -n redis exec -it redis-2 -- redis-cli
auth R3d!s@2023 #senha definida no ConfigMap
info replication
KEYS *
GET key0
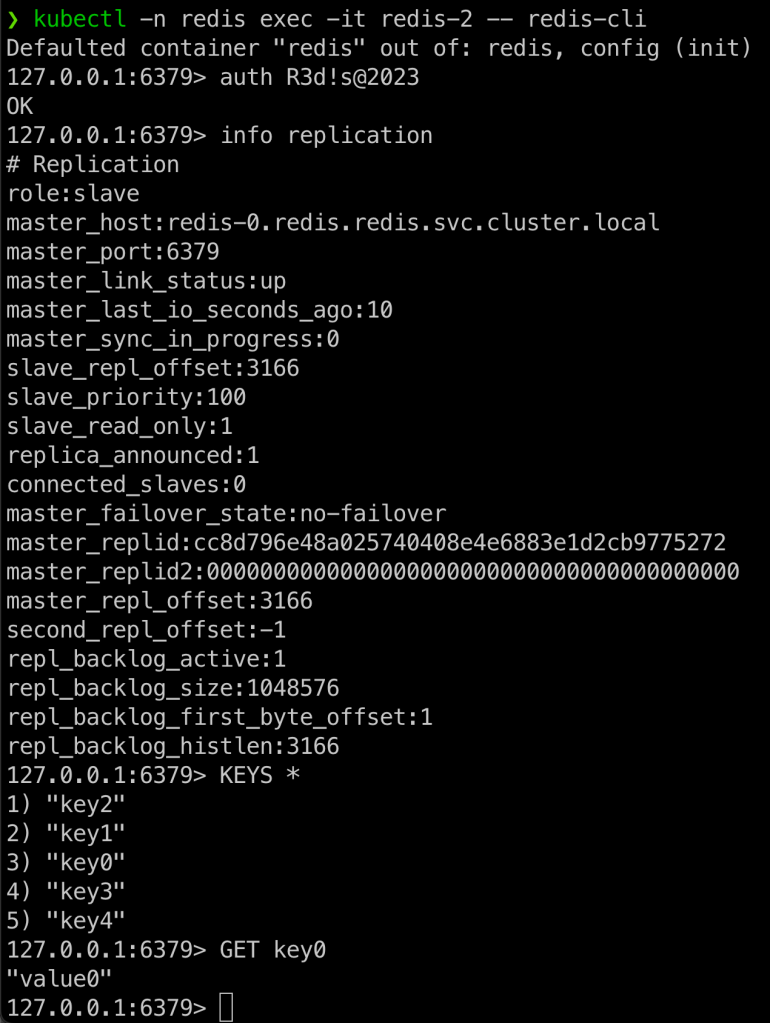
Bom gente, é isso por enquanto, podemos ver neste post como é simples executar um cluster Redis no AKS que já nos entrega disco e Load Balancer nativos para que possamos disponibilizar nossos clusters de banco de dados!
No próximo post veremos um banco de dados distribuído que gosto muito de trabalhar! Não deixe de acompanhar! Vlw!
