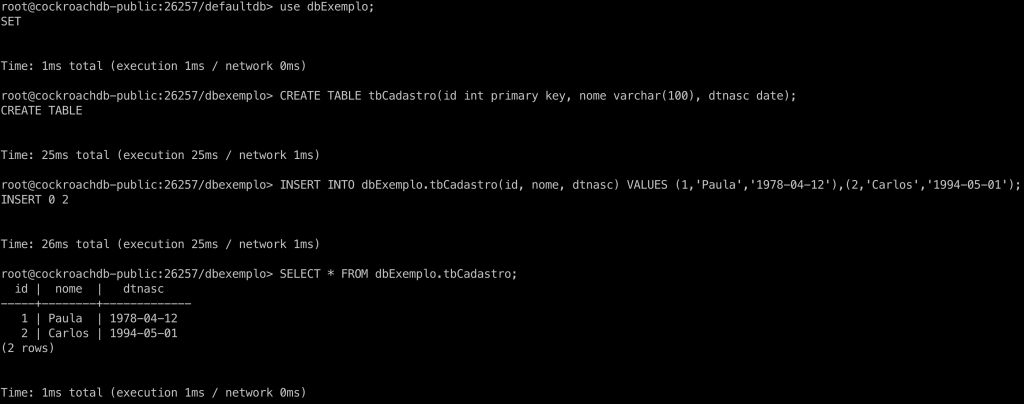
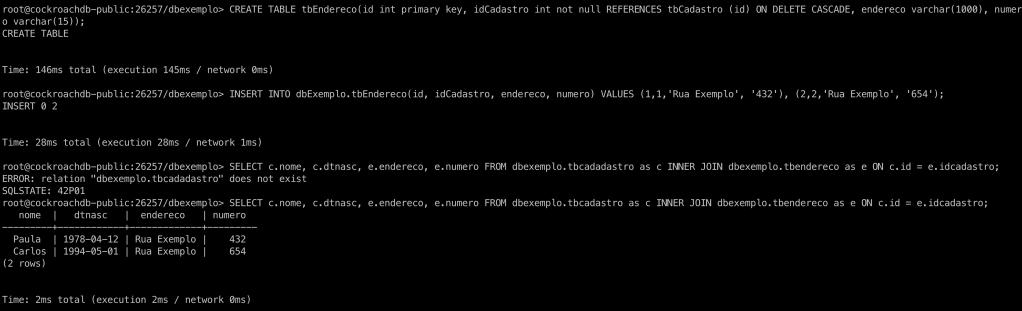
Fala galera!
Dando uma quebra na série de posts sobre bancos de dados executando no Azure Kubernetes Service, falaremos hoje de um tipo de cluster de banco de dados que eu gosto demais que é o SQL Server Failover Instance. Este é um post que fiz no blog da minha consultoria Data Tuning e resolvi trazer para meu blog pessoal revisando o conteúdo.
Para quem trabalha em ambientes tradicionais de SQL Server já deve ter ouvido falar de um dos modelos de Cluster mais consolidados do mercado: o Microsoft Failover Cluster.
O Failover Cluster nada mais é que uma feature de Alta Disponibilidade implementada no Windows Server que nos possibilita criar ambientes resilientes e com contigencia de maquina. O SQL Server, por sua vez, se beneficia desta feature para disponibilizar de forma redundante instancias de banco de dados.
No ano passado a Microsoft colocou em General Availability uma das features que eu pelo menos ainda não vi nas demais clouds que é a de Discos Compartilhados (Shared Disks) para servidores Windows. A partir dai podemos contar com esta capacidade para prover serviços onde há a necessidade de storage centralizada para habilitar redundancia de servidores.
Neste post veremos como criar uma infraestrutura completa de SQL Server Failover Cluster Instance. Os coponentes que vamos provisionar são:
- Um servidor Windows Server 2019 de domínio ou Active Directory Domain Controller;
- Dois servidores Windows Server 2019 com SQL Server 2019 Developer CU8 em Failover Cluster;
- 3 discos Premium SSD que serão compartilhados entre os servidores de SQL Server;
- Um balanceador de carga (Internal Load Balancer ou ILB) para conectividade com a instancia SQL Server em Cluster.
Criação dos Pré-Requisitos
Iremos iniciar pela criação do Resource Group no Azure para concentrar nossos recursos.


Um dos pré-requisitos para utilização de Shared Disks no Azure é que as maquinas que farão uso deste recurso precisam ficar próximas, ou seja, no mesmo Data Center, desta forma precisamos criar um Placement Group e um Avalability Sets. Mais infos na documentação da Microsoft: Share an Azure managed disk across VMs – Azure Virtual Machines | Microsoft Docs



Aqui basta selecionar o Resource Group, colocar um nome para o recurso e selecionar a quantidade de Fault Domains, neste caso coloquei o máximo. Depois clique em Advanced:

Selecione o Proximinity Placement Group já criado e crie o recurso:

Criação dos Servidores no Azure
Agora vamos criar a instancia que será utilizada como Domain Controller da nossa infraestrutura:

Preencha as informações na aba Basic se atentando para a utilização do Availability Set uma vez que é pré requisito para este tipo de implementação:

Continuando na aba Basic, escolha o sistema operacional (Neste caso Windows Server 2019) e o tamanho da maquina (Neste caso estou utilizando uma instancia pequena para média que é uma Standard_B2ms), coloque um usuario e senha para acessar a maquina e deixe a porta RDP habilitada para acesso externo (Isso apenas se for Lab, para produção não habilite a porta para acesso pela internet!):

Na aba Disks, escolha um tipo de disco, neste caso utilizei um Standad SSD que é mais que o suficiente para uma maquina de Active Directory.

Na Aba Networking, crie uma Rede e selecione o CIDR de rede que será utilizado para nossa infraestrutura, também crie um IP público para acesso ao servidor. Os demais parâmetros deixe como esta e siga para próxima aba:

Na aba Management, desça até enxergar a opção de Auto-shutdown, habilite essa opção para ambientes que podem ser desligado em um determinado momento do dia assim como este ambiente de laboratório:

Na aba Advanced, garanta que o Proximity Placement Group criado no começo da post esteja selecionado. Clique em Review + Create para criar a VM de AD:

Agora vamos criar as instancias de SQL Server que vão seguir a mesma linha da instancia de Domain Controller, repita os passos a seguir tanto para instancia SQLVM01 como para SQLVM02:




Após criado todos os sevidores a visão das Virtual Machines ficará desta forma:

Instalação do Domínio Active Directory – Domain Controller
Agora vamos instalar nosso Domain Controller, clique na máquina domaincontroller, depois clique em conect e RDP, você irá ser redirecionado para uma tela para baixar o arquivo de Remote Desktop com o IP da instancia para acessa-la:





Uma vez com acesso ao servidor vamos instalar o Active Directory e promover esta maquina para Domain Controller.
Após acessar o servidor remotamente, a tela acima irá abrir automáticamente após a inicialização. Clique em Add roles and features:

Navegue até a opção Server Roles do lado direito, após chegar nesta tela, ative apenas a opção indicada na imagem:


Após a tela anterior selecione a opção Telnet Client para instalar o Telnet no servidor, usaremos ele lá no final do post. Após isso, clique em Next, Next e siga com a instalação:

Após a instalação, no canto superior direito da tela de Server Manager haverá essa bandeirinha com um símbolo de interrogação, clique nela e depois clique na opção indicada: Promote this sever to a domain controller:

Nesta tela, clique em Add a new forest e coloque um nome para o seu domínio, neste caso o nome será datatuning.com (A Microsoft geralmente utiliza para seus exemplos o CONTOSO). Depois disso clique em Next:

Deixe tudo como esta e apenas coloque uma senha forte para o usuário Administrator do domínio:

Coloque o nome NetBIOS que será o nome mais simplificado, neste caso coloquei apenas DATATUNING:

Ignore os pontos de atenção e instale:

Após instalado o servidor automáticamente será incluido ao domínio criado:

Após instalado o Active Directory e ter promovido o servidor à Domain Controller precisamos agora colocar um DNS Server estático para este servidor e para os demais (que vão pegar automáticamente esta configuração). No Azure toda a configuração de rede tem ser feita pela console ou pela cli, isso por que quem controla a rede é a plataforma e não os servidores, mesmo que sejam colocados no dominio.
É importante fazer essa configuração pois se não as máquinas de SQL Server não reconhecerão o servidor de domínio.
Para isso, vá até o Portal da Azure, acesse os servidores de SQL, vá até a opção Networking e clique na placa de rede do servidor, após acessar a placa clique na opção DNS Servers, marque a opção custom e coloque o IP do servidor de domínio que neste caso é o 10.0.0.4.
Após efetuar essas alterações, reinicie todos os servidores SQLVM01 e SQLVM02:


Após efetuada essas configurações agora iremos colocar nossos servidores SQL Server no domínio. Para isso, acesse os servidores remotamente e siga os passos a seguir:
Após acessar os servidores de banco de dados, abra o Explorer e clique com o botão direito em This PC e depois em Properties para abrir a tela de System. Após chegar nesta tela, clique em Advanced system settings.

Depois, na Computer Name, clique no botão Change…

Marque a opção Domain e coloque o nome do domínio. No usuário e senha, utilize a conta de domínio do admindt (Criada na instalação do AD) e senha e clique em OK.

Se estiver tudo certo com a rede e com o usuário e senha o seguinte Pop-Up deverá aparecer. Caso o servidor não esteja conseguindo chegar no servidor de domínio, revise a configuração de DNS Servers efetuada anteriormente:

Após a inclusão do servidor de domínio poderemos confirmar que o mesmo foi incluido entrando em System. Repita os passos para o servidor SQLVM02.

Instalação e Configuração do Failover Cluster
Uma vez que os servidores estão no domínio agora poderemos seguir com a instalação do Cluster Failover nos servidores. Lembram que no começo do Post eu disse que o Cluster Failover é uma feature do Windows Server e não do SQL Server que apenas se beneficia dela? Então, agora vamos ativar esta feature nos servidores SQLVM01 e SQLVM02. Só seguir o passo a passo simples abaixo:



Após instalado a feature aperte Super(simbolo do Windows) + Q ou vá até a aba de buscas do Windows e procure por Failover Cluster Manager. Após abrir o mesmo, clique em Create Cluster…:

Aqui iremos selecionar todos os nós que participarão do Cluster SQL Server, sendo assim, iremos selecionar as máquinas SQLVM01 e SQLVM02:

Após selecioná-las, clique em Next:

Coloque um nome para o Cluster, este será o Network Name do Cluster Failover e será registrado no DNS do AD que instalamos. Clique em Next, Next e crie o Cluster.

Após a instalação a tela abaixo aparecerá:

Após a instalação ser concluída, verifique na opção Nodes do FCI Manager se ambos os nós do Cluster já estão fazendo parte do mesmo:

Criação e Configuração dos Discos Compartilhados – Shared Disks
Agora vamos criar os discos compartilhados (Shared Disks) que serão gerenciados pelo Cluster Failover. Aqui você pode utilizar tanto o Console existente na própria Azure como o seu PowerShell. Via PS você precisará instalar o Azure CLI. A seguir esta o comando para criação dos 3 Shared Disks que iremos utilizar em nossas VMs, todos serão Premium SSD com 1TB de espaço:
az disk create -g dt_disk_shared -n azuresqlfcidisk1 --size-gb 1024 -l eastus --sku Premium_LRS --max-shares 2
az disk create -g dt_disk_shared -n azuresqlfcidisk2 --size-gb 1024 -l eastus --sku Premium_LRS --max-shares 2
az disk create -g dt_disk_shared -n azuresqlfcidisk3 --size-gb 1024 -l eastus --sku Premium_LRS --max-shares 2Este é o resultado depois de criado:

Agora vamos relacionar o disco criado às nossas VMs de SQL Server. Só executar o comando a seguir no PowerShell (Neste caso utilizei o console da Azure):
$resourceGroup = "dt_disk_shared"
$location = "eastus"
$vm = "sqlvm01"
$vm = Get-AzVm -ResourceGroupName $resourceGroup -Name "sqlvm01"
$dataDisk = Get-AzDisk -ResourceGroupName $resourceGroup -DiskName "azuresqlfcidisk1"
$vm = Add-AzVMDataDisk -VM $vm -Name "azuresqlfcidisk1" -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 0
update-AzVm -VM $vm -ResourceGroupName $resourceGroup
$resourceGroup = "dt_disk_shared"
$location = "eastus"
$vm = "sqlvm02"
$vm = Get-AzVm -ResourceGroupName $resourceGroup -Name "sqlvm01"
$dataDisk = Get-AzDisk -ResourceGroupName $resourceGroup -DiskName "azuresqlfcidisk1"
$vm = Add-AzVMDataDisk -VM $vm -Name "azuresqlfcidisk1" -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 0
update-AzVm -VM $vm -ResourceGroupName $resourceGroupResultado esperado após ter o disco relacionado à maquina:

Execute o mesmo comando alterando a variável $vm para “sqlvm02” para relacionar o disco na outra máquina também.
Agora vamos reconhecer os discos no servidor onde o Cluster estiver disponivel, para conferir qual é o nó do cluster que é o owner neste momento abra o Failover Cluster Manager, clique no nome do Cluster e confira o Current Host Server, neste meu caso o owner neste momento é o SQLVM02, então, seguirei os próximos passos neste nó:

Aperte Super + Q ou clique na lupa ao lado do icone Iniciar, escreva Computer Management e abra a tela.

Com a tela aberta, clique em Disk Management, caso os passos os comandos de alocação de discos executados anteriormente na Console do Azure tenham dado certo então automaticamente deverá aparecer um Pop-Up de Initialize Disk. Os discos deverão aparecer como Disk 2, Disk 3 assim por diante, selecione os mesmos, depois selecione em MBR (Master Boot Record) e então clique em OK:

Os discos irão aparecer como unidades sem Volume montado, assim, clique com o botão direito do mouse nos discos que queira montar uma unidade. Um Pop-Up de formatação irá aparecer. Formate o Volume como NTFS, 64K de alocação (Padrão para discos de SQL Server) e de um nome para o volume, neste caso eu coloquei SQLBIN, selecione Perform a quick format e despois clique em OK:

Esse deverá ser o resultado após a formatação do disco:

Uma vez que o disco esteja formatado e disponivel no servidor podemos então adiciona-lo no Cluster. Abra o Failover Cluster Manager, clique em Disks e depois em Add Disk:

Este Pop-Up irá aparecer, marque os discos disponíveis e adicione ao cluster:

Agora possuímos um disco disponível para o cluster que poderá compartilhado para os serviços instalados no mesmo, neste caso será o SQL Server que irá compartilhar os discos entre os dois nós do Cluster. Por isso chamamos estes de Discos Compartilhados:

Agora relacione os demais discos aos servidores, perceba que os comandos são bem parecidos, isso por que estamos adicionando mais dois discos e apresentando estes para os dois nós, assim como fizemos com o primeiro disco. Execute os comandos a seguir no Cloud Shell do Azure como PowerShell:
$resourceGroup = "dt_disk_shared"
$location = "eastus"
$vm = "sqlvm01"
$dataDisk = Get-AzDisk -ResourceGroupName $resourceGroup -DiskName "azuresqlfcidisk2"
$vm = Add-AzVMDataDisk -VM $vm -Name "azuresqlfcidisk2" -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 2
update-AzVm -VM $vm -ResourceGroupName $resourceGroup
$resourceGroup = "dt_disk_shared"
$location = "eastus"
$vm = "sqlvm01"
$dataDisk = Get-AzDisk -ResourceGroupName $resourceGroup -DiskName "azuresqlfcidisk3"
$vm = Add-AzVMDataDisk -VM $vm -Name "azuresqlfcidisk3" -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 3
update-AzVm -VM $vm -ResourceGroupName $resourceGroup
$resourceGroup = "dt_disk_shared"
$location = "eastus"
$vm = "sqlvm02"
$dataDisk = Get-AzDisk -ResourceGroupName $resourceGroup -DiskName "azuresqlfcidisk2"
$vm = Add-AzVMDataDisk -VM $vm -Name "azuresqlfcidisk2" -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 2
update-AzVm -VM $vm -ResourceGroupName $resourceGroup
$resourceGroup = "dt_disk_shared"
$location = "eastus"
$vm = "sqlvm02"
$dataDisk = Get-AzDisk -ResourceGroupName $resourceGroup -DiskName "azuresqlfcidisk3"
$vm = Add-AzVMDataDisk -VM $vm -Name "azuresqlfcidisk3" -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 3
update-AzVm -VM $vm -ResourceGroupName $resourceGroupVerifique que na imagem as Luns (Logical Unit Numbers) são diferentes, isso por que para alocar os discos nos servidores precisamos dar ID’s diferentes para cada disco dentro dos servidores:

Assim como o outro disco, acesse o Computer Management, vá até Disk Management, selecione os discos adicionados e selecione MBR, depois clique em OK.

Crie os volumes nos discos. Neste caso dei os labels SQLDATA e SQLLOG para separar os arquivos de Dados e Log em discos diferentes, isso é uma boa prática para que não haja concorrencia de Leitura e Escrita entre arquivos de Dados e Log dos bancos de dados. Se possível, faça o mesmo para TEMPDB.

Os discos ficaram apresentados para os servidores desta forma:

Entre no Failover Cluster Manager, clique em Disks e depois em Add Disk. Os dois discos deverão aparecer já marcados. Clique em OK para adicionar os discos:


Uma vez que os discos forem adicionados você terá esta visão no console do Cluster e também se abrir o Meu Computador ou “This PC” você os enxergará e poderá acessa-los.

Instalação do SQL Server em Cluster
Já fizemos um monte de coisas né? Poisé, mas agora vamos iniciar a instalação do nosso SQL Server. Para quem já instalou uma instância de SQL Server Stand-Alone não verá grandes diferenças aqui. A instalação em cluster se diferencia principalmente na parte dos discos e rede, todos os passos serão parecidos com a instalação normal do SQL.
Para este Lab iremos utilizar o SQL Server 2019 Developer Edition, porém, você poderá utilizar a versão de sua escolha, alguns steps serão diferentes pois na versão 2019 algumas configurações de arquivos foram adicionados mas as configs de Cluster permanecem as mesmas desde o 2012.
Vou colocar apenas as telas as quais teremos alguma ação a ser tomada, para as demais é só clicar em Next. Abra o Setup do SQL Server, clique na aba Installation e depois clique em New SQL Server failover cluster installation:

Na tela Feature Selection selecione apenas as opções: Database Engine Service (Ao selecionar esta outras serão automaticamente selecionadas, pode deixar assim mesmo) e todos os Clients que tiver:

Na tela Instance Configuration de um nome para sua instância e deixe o Default instance selecionado.

Na tela Cluster Disk Selection selecione todos os discos disponíveis:

Na tela Cluster Network Configuration tome cuidado pois é aqui que determinaremos qual é o ip que será utilizado para acesso á instância por meio do Cluster:
Marque o Check Box do lado esquerdo, desmarque a opção de DHCP e coloque um IP que não esteja sendo utilizado na sua rede (Isso é muito importante pois se o IP não conseguir ser alocado na instalação do SQL Server a mesma poderá vir a falhar!). Neste caso utilizei o IP 10.0.0.10.

Aqui na tela de Server Configuration coloque um usuário e senha existente no Domínio AD. É importante colocar um usuário de domínio pois seu gerenciamento será centralizado. Para não ter dores de cabeça insira este usuario no grupo Administrators local dos servidores. Marque a opção Grant Perform Volume Maintenance Task privilege to SQL Server Database Engine Service para melhorar a performance na criação de arquivos do SQL Server.

Marque a opção Mixed Mode (caso você queira utilizar autenticação via SQL), sete a senha do usuário SA e inclua seu usuário na server role SysAdmin:

Nesta mesma tela, navegue até a aba TempDB e altere o Path de armazenamento dos arquivos TempDB, neste caso estou armazenando os arquivos em uma pasta criada no volume SQLBIN (F:\). Deixe as demais configs da forma como estão.

Na aba Data Directories altere os caminhos padrão para os arquivos de Data files e Log files para os volumes que adicionamos que são SQLDATA (H:\) e SQLLOG (G:\).

Na aba Memory marque a opção Recommended para deixar a memória acomodada conforme o SQL Server sugerir. Você poderá alterar essa configuração posteriormente, mas tenha em mente que você precisará deixar um pouco de memória para o Sistema Operacional, nesta tela o instalador do SQL Server já faz um cálculo e entre uma quantidade ideal para o funcionamento da instância de banco de dados:

Siga até a tela de instalação.

Após a instalação deveremos ver uma tela como está, caso ocorra algum erro na instalação de algum componente veremos um icone vermelho ao lado do componente e o Status Failure:

Uma vez instalado já conseguiremos visualizar o Resource Group do SQL Server no Failover Cluster Manager, destaque para os discos que foram “attachados” ao recurso do SQL Server:

Agora temos um SQL Server instalado em Cluster más ainda não acabamos! O SQL foi instalado apenas em um dos nós, agora precisamos instalar os binários no outro nó para que possamos chavear os recursos sempre que necessário.
Os passos a partir daqui serão executados no servidor SQLVM01 que é o par que não possui os recursos disponíveis:
No servidor par, abra o instalador do SQL Server, vá até a aba Installation e depois clique em Add node to a SQL Server failover cluster.

Esta é uma tela informativa, mostra em qual servidor iremos instalar os binários do SQL.

Aqui iremos utilizar o mesmo usuário e senha que utilizamos na instalação do outro nó. Este será o usuario que irá gerenciar os serviços do SQL.

Next, next… finish.

Após concluída a instalação veremos a seguinte tela:

Agora sim! Após fazer o Add Node do nosso outro nó do cluster agora poderemos já testar o chaveamento dos recursos do SQL Server no cluster.
Para isso vá até o Console do Failover Cluster Manager em qualquer um dos nós, clique com o botão direito em cima do resource group do SQL, depois em Move e então clique em Best Possible Node. Como temos apenas dois nós o Cluster irá chavear os recursos do servidor SQLVM02 para o SQLVM01:

Chaveamento em andamento, o Cluster irá “baixar” todos os recursos e depois irá iniciar todos no outro nó.

Pronto! Agora o nó que manda é o SQLVM01:

Se você abrir o Meu Computador (This PC) no servidor SQLVM01 verá os discos disponiveis para acesso.

Acessando o SQL Server FCI no Azure
Achou que acabou? Se você em um ambiente OnPremises talvez poderiamos já dar a instalação como concluída, porém, no Azure ainda temos mais recursos a serem criados, pois, como eu disse la em cima do Post a parte de rede do Azure é gerenciada pela plataforma e não pelos servidor, sendo assim, precisamos configurar um componente para que os servidores existentes em nossa cloud possam acessar nossa instancia SQL.
Neste caso iremos provisionar um Internal Load Balancer (ILB), este será o responsável por entregar um IP de acesso para nossa infraestrutura de banco de dados onde os demais servidores e recursos provisionados na Azure possam acessá-lo.

Na tela de criação do load balancer selecione o Resource Group, dê um nome para o recurso, em Type marque Internal e em SKU pode deixar como Basic mesmo. Depois escolha o Virtual network igual o dos servidores e coloque um IP Estático, neste caso coloquei 10.0.0.100.

Após o ILB ter sido criado, acesse o recurso e configure os seguintes componentes: Backend pool, Health probe e Load Balance Rule.
No Backend Pool, de um nome, marque IPv4, escolha a opção Virtual Machines e adicione os servidores que fazem parte do cluster.

No Health probe adicione o protocolo TCP, a porta 59999 que será utilizada para verificar se o recurso (Neste caso o servidor) esta no ar e saudável e aumente o intervalo de verificação para 10 segundos.

No Load Balancer Rule basicamente iremos utilizar a porta 1433 (Padrão do SQL Server) para os campos de porta, selecionar o Backend Pool e Health probe já criados e depois alterar o Floating IP para Enabled.

Pronto, uma vez efetuada essas configurações damos por concluida a instalação do nosso Load Balancer.
Por garantia libere as portas 1433 e 59999 no firewall dos servidores SQL Server e no Security Group dos servidores na console do Azure como está abaixo:
Neste caso, como é um ambiente Lab eu libere para qualquer um acessar. Para ambientes que não sejam de laboratório NUNCA faça isso, libere as portas apenas para os recursos que realmente possam acessar os servidores.

Caso você não queira utilizar o ILB para liberar o acesso aos servidores de SQL Server você poderá utilizar um Distributed Network Name (DNN). Essa configuração é uma boa caso você tenha uma infra que esteja no mesmo dominio que os servidores SQL Server ou que tenham acesso ao mesmo DNS.
Para checar os Pré-requisitos para utilizar esta feature acesse o link na documentação, o mais importante é que esta disponível apenas para SQL Server 2019 Cumulative Update 2, para o nosso Lab ta valendo.
Abra o PowerShell em um dos nós do Failover Cluster e execute os comandos a seguir:
Add-ClusterResource -Name dnn-demo -ResourceType "Distributed Network Name" -Group "SQL Server (MSSQLSERVER)"
Get-ClusterResource -Name dnn-demo | Set-ClusterParameter -Name DnsName -Value FCIDNN
Start-ClusterResource -Name dnn-demoUm recurso como este da imagem abaixo irá aparecer no Resource group do SQL Server no console do Cluster:

Após efetuada essas configurações, vá até o servidor de Domain Controller, instale o SQL Server Management Studio e acesso o SQL Server, neste caso, você pode utilizar tando o DNN que acabamos de criar como o IP do ILB que criamos anteriormente:

Conclusões
Bom meu povo é isso! Bastante coisa né? Poisé.
Grande parte deste passo a passo pode ser utilizado em um ambiente OnPremises pois a unica diferença será a configuração dos discos, desta forma, se você puder contar com uma storage centralizada em sua infraestrutura você poderá utilizar a melhor infraestrutura de cluster de alta disponibilidade já construida.
Grande parte dos ambientes que eu e meus amigos e sócios aqui na Data Tuning lidamos hoje utilizam essa arquitetura de alta disponibilidade e posso dizer com propriedade e experiência que é uma das mais estáveis e tranquilas de se administrar (Se você não tiver backe-level, claro! rs).
Agradeço imensamente ao mestre Diego Miranda que me ajudou na reprodução deste Lab!
Espero que tenha adicionado alguma coisa para vocês! Fico a disposição para possíveis dúvidas e sugestões de novos temas para posts.
Valeu pessoal!